I am a postdoctoral researcher at the Software Evolution and Analysis Laboratory (SEAL) at UCLA, working with Prof. Miryung Kim.
My research interests lie in program analysis and software testing, with a focus on making program analysis scalable to address the challenges associated with the scale and complexity of software systems. I aim to achieve practical software testing in real-world scenarios by utilizing statistical methods to analyze dynamic information from program execution, facilitating the reasoning of a program’s semantic properties and addressing empirical challenges in software testing.
I have been invited to serve as a Program Committee (PC) of the International Symposium on Empirical Software Engineering and Measurement (ESEM 2026).
Mar, 2026
Our paper “Evaluating LLM-based Regression Test Generation” has been accepted to appear at FSE 2026! Congrats to our amazing team!
Jan, 2026
I have been invited to serve as a Program Committee (PC) of the 41st IEEE/ACM International Conference on Automated Software Engineering (ASE 2026).
Dec, 2025
Our paper “In Bugs We Trust? On Measuring the Randomness of a Fuzzer Benchmarking Outcome” has been accepted to appear at FSE 2026! Congrats to our amazing team!
Oct, 2025
Our paper “Dependency-aware Residual Risk Analysis” has been accepted to appear at ICSE 2026! Congrats, Marcel!
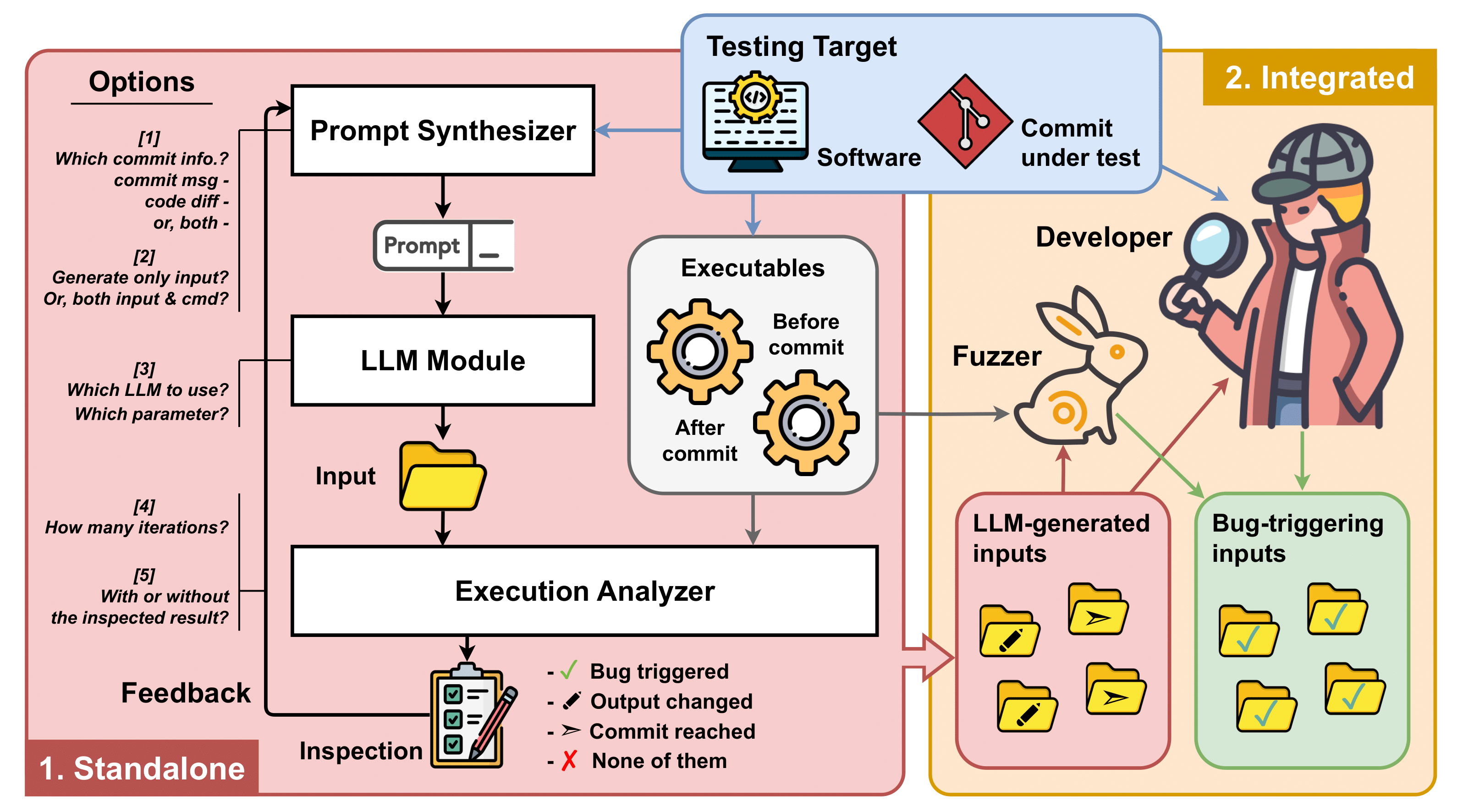
Large Language Models (LLMs) have shown tremendous promise in automated software engineering. In this paper, we investigate the opportunities of LLMs for just-in-time regression test generation for programs, like parsers, interpreters, or compilers, that take highly structured, human-readable inputs. When a new bug fix or code change is committed, the repository (as part of the CI/CD workflow) runs an LLM for a few minutes to generate regression test cases for that commit that exercise the changed code and potentially trigger any bugs.
Specifically, we investigate LLM-based regression test generation as a machine translation task that takes the developer-provided commit message, the code change, and the name of the input format (e.g., XML) and produces regression test cases for the described change in the given input format. In our experiments testing 72 commits to Mujs, Libxml2, Poppler, JerryScript, Z3, PHP, JQ, and MicroPython, our feedback-directed, zero-shot LLM-based prototype Cleverest performed well, even if we did not provide the code change. In under 2 minutes, on average, Cleverest found as many bugs as the state-of-the-art directed greybox fuzzer WAFLGo in 24 hours, even though WAFLGo started with a commit-reaching seed corpus in the majority of cases. If we amplify the Cleverest-generated test cases using those as a seed corpus in coverage-guided greybox fuzzing, the number of bugs found doubles. We call the integration with fuzzing as ClevFuzz.
In addition, we found that some commit messages are more expressive than others, thus we wonder how this impacts the effectiveness of Cleverest. Our results above demonstrate that Cleverest picks up on the change intention. For instance, if the commit message describes that this patch changes how floating point variables are treated in the Mujs JavaScript interpreter, then Cleverest generates JavaScript programs that contain floating point variables. To study the impact of expressiveness, we change the commit messages minimally to reduce and increase the information in the commit message, respectively, and find a substantial impact on effectiveness. For instance, adding 17 words on average (max. 43) to make ineffective commit messages more expressive significantly increased the number of bugs found.
@inproceedings{FSE26-llmregression,title={Evaluating LLM-based Regression Test Generation},author={Liu, Jing and Lee, Seongmin and Losiouk, Eleonora and Böhme, Marcel},booktitle={Proceedings of the {{ACM}} International Conference on the Foundations of Software Engineering},year={2026},month=jul,}
FSE
In Bugs We Trust? On Measuring the Randomness of a Fuzzer Benchmarking Outcome
Ardi Madadi*, Seongmin Lee*, Cornelius Aschermann, and Marcel Böhme
In Proceedings of the ACM International Conference on the Foundations of Software Engineering, Jul 2026
In Google’s FuzzBench platform, we find that the outcome of coverage-based evaluation more strongly agrees with the outcome of a bug-based evaluation than an independent bug-based evaluation itself. Recently, Böhme et al. found that despite a very strong correlation between coverage achieved and bugs found, there is no strong agreement between the outcome of a coverage- and a bug-based evaluation: The fuzzer best at achieving coverage may be the worst at finding bugs. However, in trying to explain this moderate agreement, we wondered whether the outcome of bug-based benchmarking itself is perhaps much more “noisy” and turned to applied statistics to develop the tools necessary to investigate our hypothesis.
In this paper, we call this degree of “noisiness” of a benchmarking outcome the concordance of the benchmarking procedure and quantify it using a measure of statistical reliability widely used in psychology, called mean split-half reliability, i.e., the expected agreement on the benchmark outcome between two random halves of the benchmarking suite. In our experiments with FuzzBench and Magma, we find that the concordance of coverage-based benchmarking is consistently strong while that of bug-based benchmarking is weak on FuzzBench and moderate on Magma. In contrast to FuzzBench, for the Magma benchmark suite (which was designed for bug-based evaluation) a coverage-based evaluation does not predict the outcome of a bug-based evaluation better than an independent bug-based evaluation.
Moreover, to demonstrate the utility of concordance also for developers of benchmarking suites, we investigate concordance as a measure of benchmarking efficiency, as in green fuzzer benchmarking. We empirically confirm that the resources of a procedure with higher concordance can be reduced more substantially (in terms of campaign length or benchmark sampling size) while maintaining a similar benchmark outcome as a procedure with lower concordance. We report the corresponding savings in terms of carbon emissions.
@inproceedings{FSE26-concordance,title={In Bugs We Trust? {{On}} Measuring the Randomness of a Fuzzer Benchmarking Outcome},author={Madadi, Ardi and Lee, Seongmin and Aschermann, Cornelius and Böhme, Marcel},booktitle={Proceedings of the {{ACM}} International Conference on the Foundations of Software Engineering},year={2026},month=jul,}
S&P
Cottontail: LLM-Driven Concolic Execution for Highly Structured Test Input Generation
How can we perform concolic execution to generate highly structured test inputs for systematically testing parsing programs? Existing concolic execution engines are significantly restricted by (1) input structure-agnostic path constraint selection, leading to the waste of testing effort or missing coverage; (2) limited constraint-solving capability, yielding many syntactically invalid test inputs; (3) reliance on manual acquisition of highly structured seed inputs, resulting in non-continuous testing.
This paper proposes Cottontail, a new Large Language Model (LLM)-driven concolic execution engine, to mitigate the above limitations. A more complete program path representation, named Expressive Structural Coverage Tree (ESCT), is first constructed to select structure-aware path constraints. Later, an LLM-driven constraint solver based on a Solve-Complete paradigm is designed to solve the path constraints smartly to get test inputs that are not only satisfiable to the constraints but also valid to the input syntax. Finally, a history-guided seed acquisition is employed to obtain new highly structured test inputs either before testing starts or after testing is saturated.
We implemented Cottontail on top of SymCC and evaluated eight extensively tested open-source libraries across four different formats (XML, SQL, JavaScript, and JSON). Cottontail significantly outperforms baseline approaches by 30.73% and 41.32% on average in terms of line and branch coverage. Besides, Cottontail found six previously unknown vulnerabilities (six CVEs assigned). We have reported these issues to developers, and four out of them have been fixed so far.
@inproceedings{Cottontail,title={Cottontail: LLM-Driven Concolic Execution for Highly Structured Test Input Generation},booktitle={2026 {{IEEE Symposium}} on {{Security}} and {{Privacy}} ({{S\&P}}'26)},author={Tu, Haoxin and Lee, Seongmin and Li, Yuxian and Chen, Peng and Jiang, Lingxiao and B{\"o}hme, Marcel},year={2026},month=may,publisher={IEEE},}
ICSE
Dependency-aware Residual Risk Analysis
Seongmin Lee and Marcel Böhme
In Proceedings of the IEEE/ACM 48th International Conference on Software Engineering (ICSE’26), Apr 2026
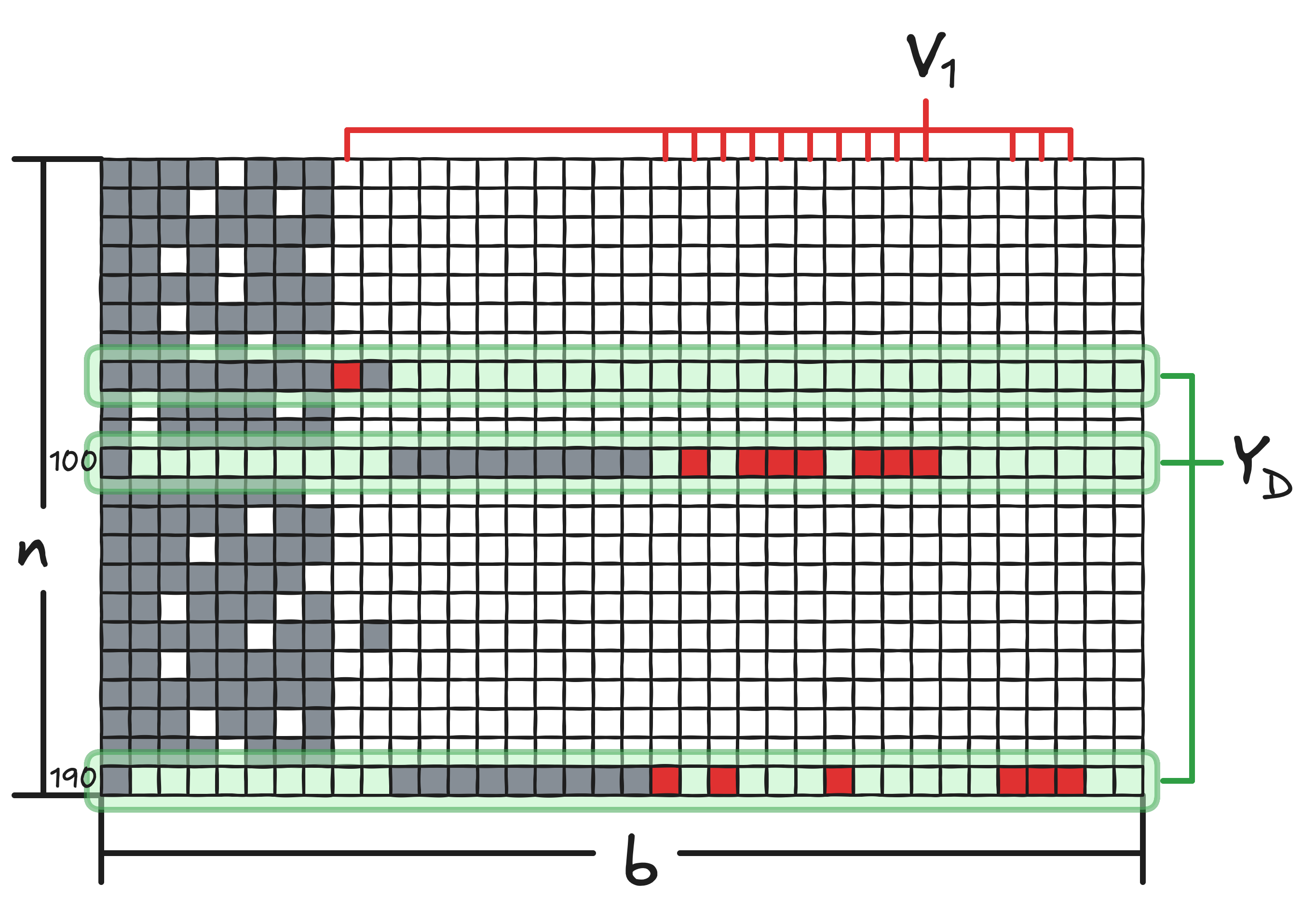
However much we test a software system, some residual risk of undiscovered bugs always remains. If we model test generation as a sampling process, the residual risk can be defined as the probability that the next test input reveals a bug. This risk is upper-bounded by the discovery probability (DP), i.e., the probability that the next test input covers new code, which itself is upper-bounded by the coverage rate, i.e., the expected number of new coverage elements per test input. Prior work introduced the Good-Turing estimator (GoTu) to estimate residual risk via coverage rate. However, we find that GoTu substantially overestimates, leading to undue optimism in bug finding because (i) the coverage rate is only a loose upper bound, and (ii) GoTu ignores dependencies among coverage elements.
We propose dependency-aware DP estimation for residual risk analysis. Our estimator directly estimates DP and accounts for dependencies among coverage elements using Ma and Chao’s sample coverage estimation. A naive implementation requires space proportional to the number of coverage elements and executions, which can be prohibitively large. To make it practical, we introduce two optimizations: dependency-aware node removal, which reduces the number of coverage elements to observe, and online singleton cluster maintenance, which eliminates the need to record observed coverage elements in each execution.
A comparison of our estimator and GoTu on real-world software from FuzzBench demonstrates a substantial reduction in estimation error. If we stopped the campaign when the estimate of residual risk fell below a certain threshold, GoTu would lead a tester to waste 7× more time than our estimator before deciding to stop. Our estimator achieves a median absolute error of only one-fifth that of GoTu. Finally, our bug-based analysis shows that our estimator achieves one to two orders of magnitude lower error than GoTu.
@inproceedings{lee2025dependenceResidual,title={Dependency-aware Residual Risk Analysis},author={Lee, Seongmin and B{\"o}hme, Marcel},booktitle={Proceedings of the {{IEEE}}/{{ACM}} 48th {{International Conference}} on {{Software Engineering}} (ICSE'26)},year={2026},month=apr,}
2025
ICSE
Accounting for Missing Events in Statistical Information Leakage Analysis
Seongmin Lee, Shreyas Minocha, and Marcel Böhme
In Proceedings of the IEEE/ACM 47th International Conference on Software Engineering (ICSE’25), Jun 2025
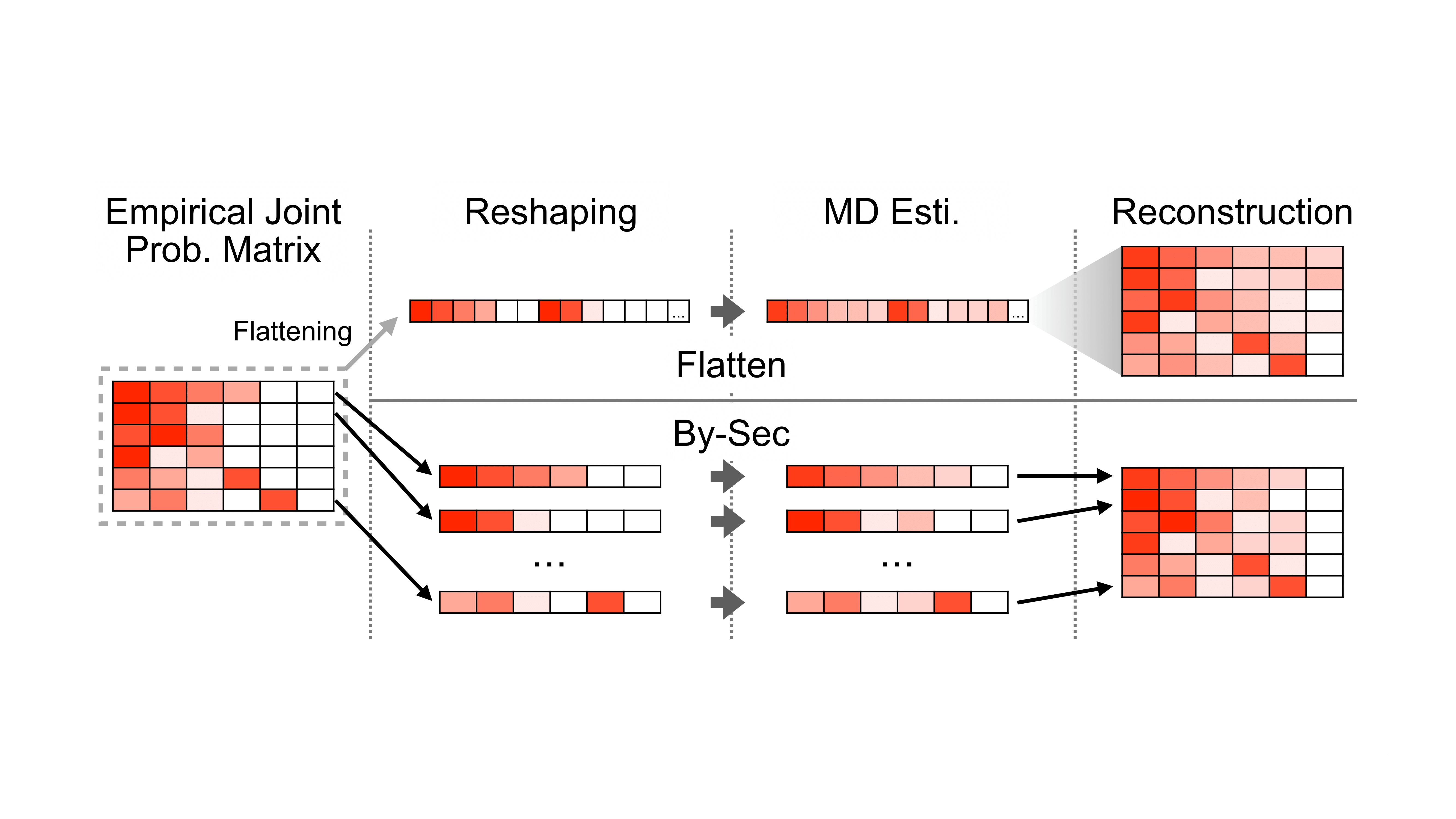
The leakage of secret information via a public channel is a critical privacy flaw in software systems. The more information is leaked per observation, the less time an attacker needs to learn the secret. Due to the size and complexity of the modern software, and because some empirical facts are not available to a formal analysis of the source code, researchers started investigating statistical methods using program executions as samples. However, current statistical methods require a high sample coverage. Ideally, the sample is large enough to contain every possible combination of secret {}times observable value to accurately reflect the joint distribution of {}langle\secret, observable{}rangle\. Otherwise, the information leakage is severely underestimated, which is problematic as it can lead to overconfidence in the security of an otherwise vulnerable program. In this paper, we introduce an improved estimator for information leakage and propose to use methods from applied statistics to improve our estimate of the joint distribution when sample coverage is low. The key idea is to reconstruct the joint distribution by casting our problem as a multinomial estimation problem in the absence of samples for all classes. We suggest two approaches and demonstrate the effectiveness of each approach on a set of benchmark subjects. We also propose novel refinement heuristics, which help to adjust the joint distribution and gain better estimation accuracy. Compared to existing statistical methods for information leakage estimation, our method can safely overestimate the mutual information and provide a more accurate estimate from a limited number of program executions.
@inproceedings{lee2024accounting,title={Accounting for {{Missing Events}} in {{Statistical Information Leakage Analysis}}},booktitle={Proceedings of the {{IEEE}}/{{ACM}} 47th {{International Conference}} on {{Software Engineering}} (ICSE'25)},author={Lee, Seongmin and Minocha, Shreyas and B{\"o}hme, Marcel},year={2025},month=jun,publisher={Association for Computing Machinery},}
ICLR
How Much Is Unseen Depends Chiefly on Information About the Seen
Seongmin Lee and Marcel Böhme
In Proceedings of the 13th International Conference on Learning Representations (ICLR’25), May 2025
The paper was selected as ICLR’25 Spotlight (Top 5% of accepted papers).
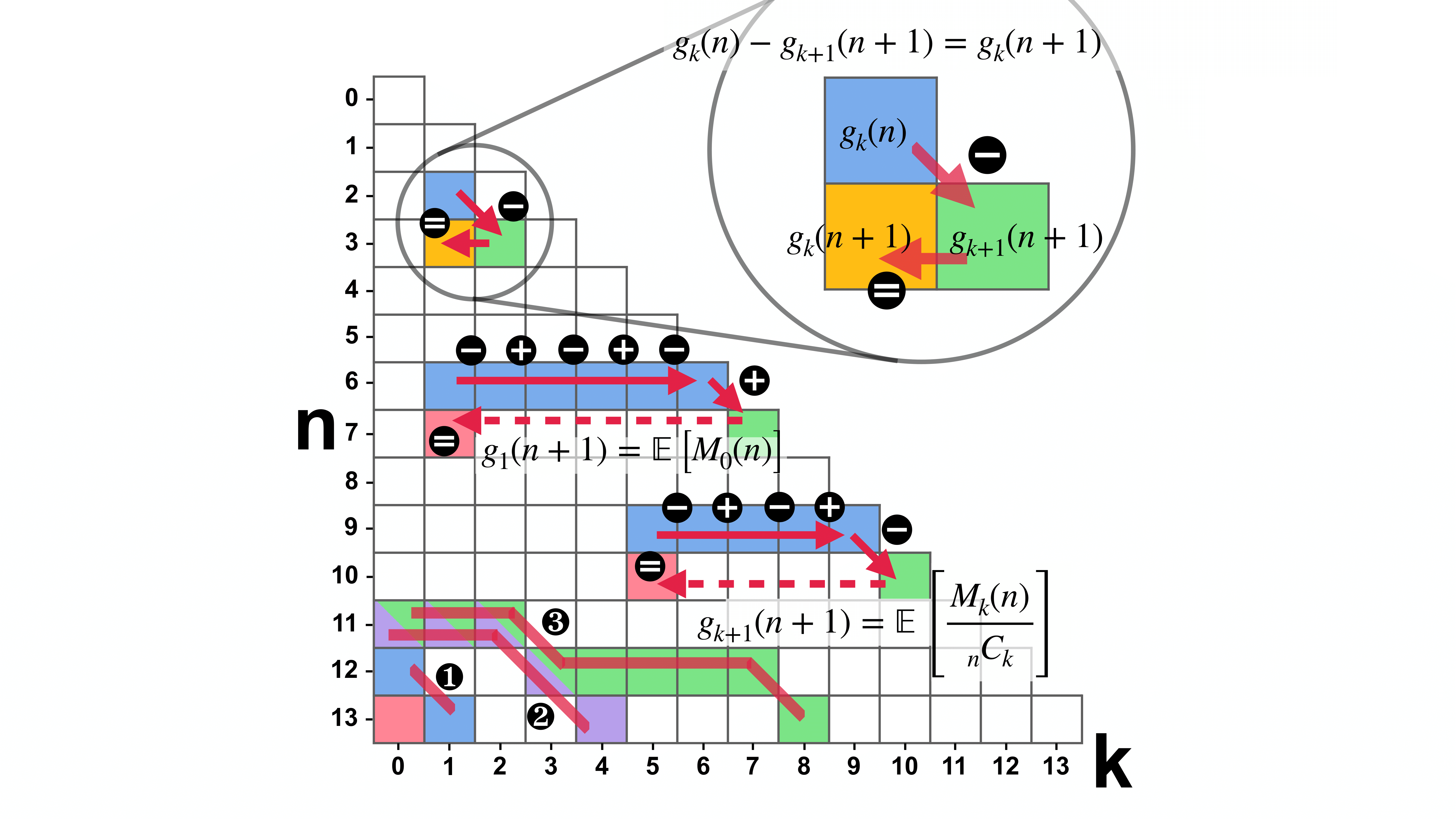
The missing mass refers to the proportion of data points in an unknown population of classifier inputs that belong to classes not present in the classifier’s training data, which is assumed to be a random sample from that unknown population. We find that in expectation the missing mass is entirely determined by the number \f_k of classes that do appear in the training data the same number of times and an exponentially decaying error. While this is the first precise characterization of the expected missing mass in terms of the sample, the induced estimator suffers from an impractically high variance. However, our theory suggests a large search space of nearly unbiased estimators that can be searched effectively and efficiently. Hence, we cast distribution-free estimation as an optimization problem to find a distribution-specific estimator with a minimized mean-squared error (MSE), given only the sample. In our experiments, our search algorithm discovers estimators that have a substantially smaller MSE than the state-of-the-art Good-Turing estimator. This holds for over 93% of runs when there are at least as many samples as classes. Our estimators’ MSE is roughly 80% of the Good-Turing estimator’s.
@inproceedings{leeHowMuchUnseen2025,title={How {{Much}} Is {{Unseen Depends Chiefly}} on {{Information About}} the {{Seen}}},author={Lee, Seongmin and B{\"o}hme, Marcel},year={2025},month=may,booktitle={Proceedings of the 13th International Conference on Learning Representations (ICLR'25)},}
SCP
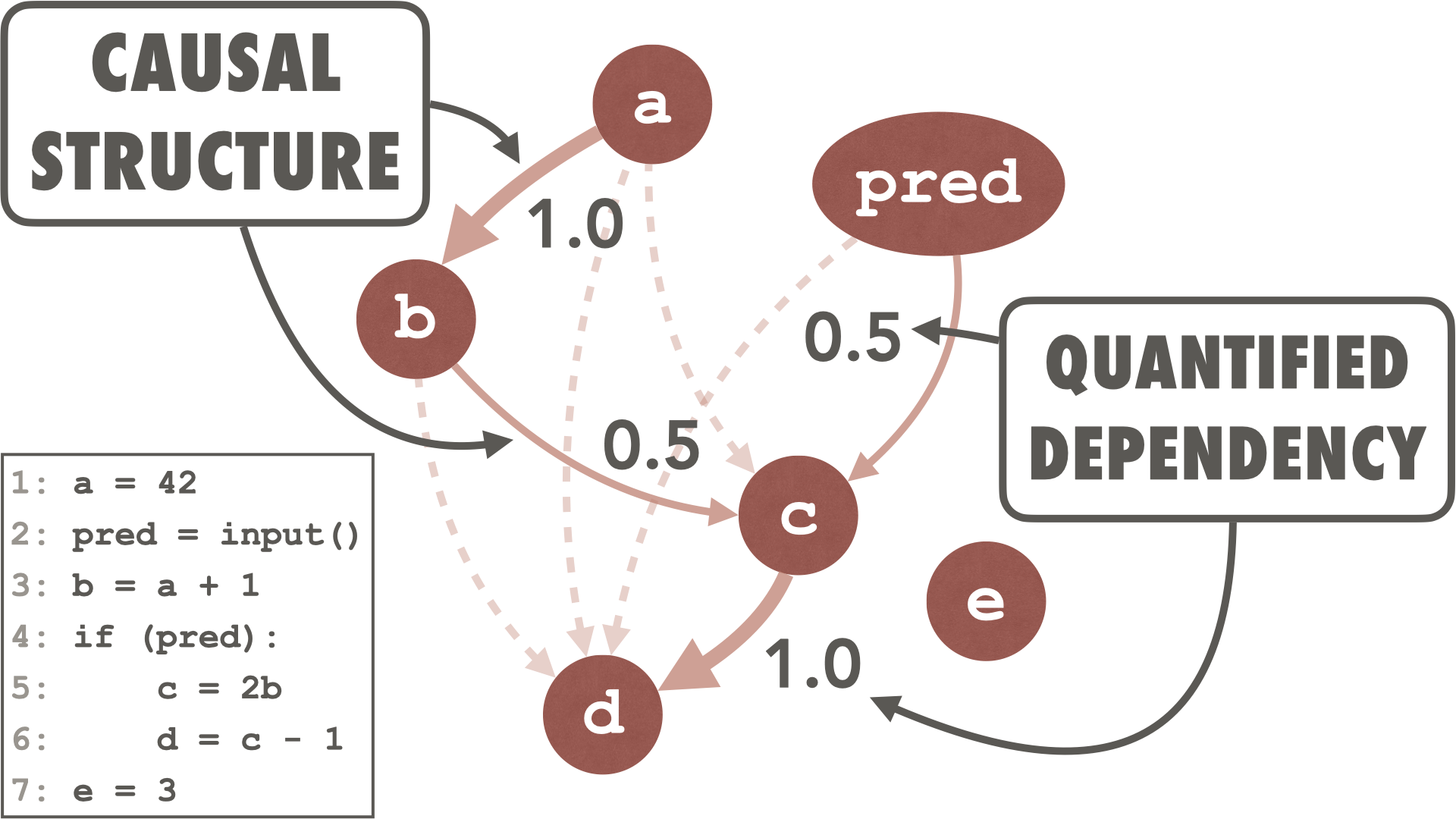
Causal Program Dependence Analysis
Seongmin Lee, Dave Binkley, Robert Feldt, Nicolas Gold, and Shin Yoo
Discovering how program components affect one another plays a fundamental role in aiding engineers comprehend and maintain a software system. Despite the fact that the degree to which one program component depends upon another can vary in strength, traditional dependence analysis typically ignores such nuance. To account for this nuance in dependence-based analysis, we propose Causal Program Dependence Analysis (CPDA), a framework based on causal inference that captures the degree (or strength) of the dependence between program elements. For a given program, CPDA intervenes in the program execution to observe changes in value at selected points in the source code. It observes the association between program elements by constructing and executing modified versions of a program (requiring only light-weight parsing rather than sophisticated static analysis). CPDA applies causal inference to the observed changes to identify and estimate the strength of the dependence relations between program elements. We explore the advantages of CPDA’s quantified dependence by presenting results for several applications. Our further qualitative evaluation demonstrates 1) that observing different levels of dependence facilitates grouping various functional aspects found in a program and 2) how focusing on the relative strength of the dependences for a particular program element provides a detailed context for that element. Furthermore, a case study that applies CPDA to debugging illustrates how it can improve engineer productivity.
@article{leeCausalProgramDependence2025,title={Causal Program Dependence Analysis},author={Lee, Seongmin and Binkley, Dave and Feldt, Robert and Gold, Nicolas and Yoo, Shin},year={2025},month=feb,journal={Science of Computer Programming},volume={240},pages={103208},issn={0167-6423},doi={10.1016/j.scico.2024.103208},}
2024
ICSE
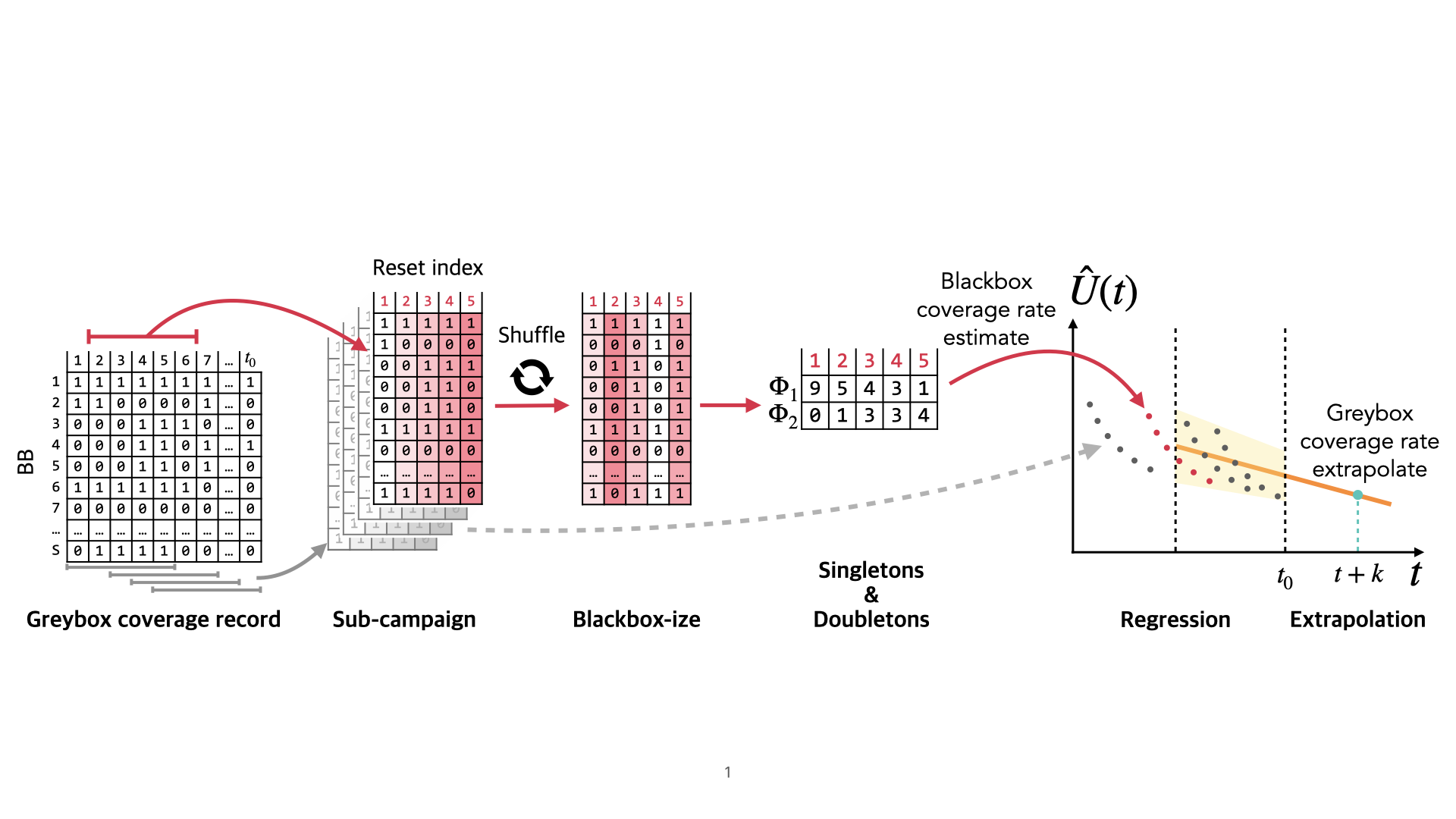
Extrapolating Coverage Rate in Greybox Fuzzing
Danushka Liyanage*, Seongmin Lee*, Chakkrit Tantithamthavorn, and Marcel Böhme
In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE’24), Apr 2024
A fuzzer can literally run forever. However, as more resources are spent, the coverage rate continuously drops, and the utility of the fuzzer declines. To tackle this coverage-resource tradeoff, we could introduce a policy to stop a campaign whenever the coverage rate drops below a certain threshold value, say 10 new branches covered per 15 minutes. During the campaign, can we predict the coverage rate at some point in the future? If so, how well can we predict the future coverage rate as the prediction horizon or the current campaign length increases? How can we tackle the statistical challenge of adaptive bias, which is inherent in greybox fuzzing (i.e., samples are not independent and identically distributed)?In this paper, we i) evaluate existing statistical techniques to predict the coverage rate U(t0 + k) at any time t0 in the campaign after a period of k units of time in the future and ii) develop a new extrapolation methodology that tackles the adaptive bias. We propose to efficiently simulate a large number of blackbox campaigns from the collected coverage data, estimate the coverage rate for each of these blackbox campaigns and conduct a simple regression to extrapolate the coverage rate for the greybox campaign.Our empirical evaluation using the Fuzztastic fuzzer benchmark demonstrates that our extrapolation methodology exhibits at least one order of magnitude lower error compared to the existing benchmark for 4 out of 5 experimental subjects we investigated. Notably, compared to the existing extrapolation methodology, our extrapolator excels in making long-term predictions, such as those extending up to three times the length of the current campaign.
@inproceedings{liyanageExtrapolatingCoverageRate2024,title={Extrapolating {{Coverage Rate}} in {{Greybox Fuzzing}}},booktitle={Proceedings of the {{IEEE}}/{{ACM}} 46th {{International Conference}} on {{Software Engineering}} ({{ICSE}}'24)},author={Liyanage, Danushka and Lee, Seongmin and Tantithamthavorn, Chakkrit and B{\"o}hme, Marcel},year={2024},month=apr,series={{{ICSE}} '24},pages={1--12},publisher={Association for Computing Machinery},address={New York, NY, USA},doi={10.1145/3597503.3639198},isbn={9798400702174},}
2023
ESEC/FSE
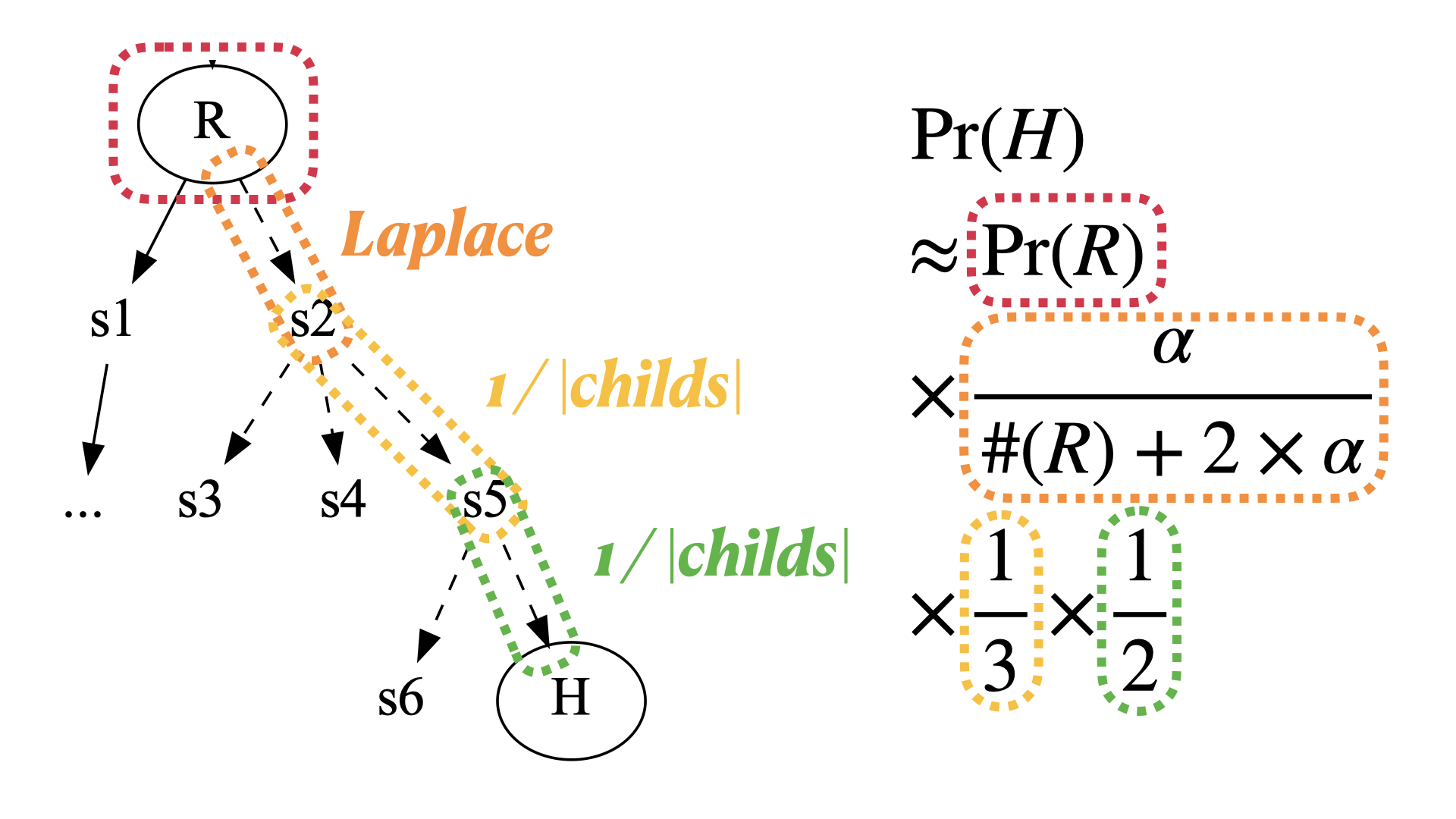
Statistical Reachability Analysis
Seongmin Lee and Marcel Böhme
In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE’23), Nov 2023
Given a target program state (or statement) s, what is the probability that an input reaches s? This is the quantitative reachability analysis problem. For instance, quantitative reachability analysis can be used to approximate the reliability of a program (where s is a bad state). Traditionally, quantitative reachability analysis is solved as a model counting problem for a formal constraint that represents the (approximate) reachability of s along paths in the program, i.e., probabilistic reachability analysis. However, in preliminary experiments, we failed to run state-of-the-art probabilistic reachability analysis on reasonably large programs. In this paper, we explore statistical methods to estimate reachability probability. An advantage of statistical reasoning is that the size and composition of the program are insubstantial as long as the program can be executed. We are particularly interested in the error compared to the state-of-the-art probabilistic reachability analysis. We realize that existing estimators do not exploit the inherent structure of the program and develop structure-aware estimators to further reduce the estimation error given the same number of samples. Our empirical evaluation on previous and new benchmark programs shows that (i) our statistical reachability analysis outperforms state-of-the-art probabilistic reachability analysis tools in terms of accuracy, efficiency, and scalability, and (ii) our structure-aware estimators further outperform (blackbox) estimators that do not exploit the inherent program structure. We also identify multiple program properties that limit the applicability of the existing probabilistic analysis techniques.
@inproceedings{leeStatisticalReachabilityAnalysis2023,title={Statistical {{Reachability Analysis}}},booktitle={Proceedings of the 31st {{ACM Joint European Software Engineering Conference}} and {{Symposium}} on the {{Foundations}} of {{Software Engineering}} ({{ESEC}}/{{FSE}}'23)},author={Lee, Seongmin and B{\"o}hme, Marcel},year={2023},month=nov,series={{{ESEC}}/{{FSE}} 2023},pages={326--337},publisher={Association for Computing Machinery},address={New York, NY, USA},doi={10.1145/3611643.3616268},isbn={9798400703270},}