Seongmin Lee

+1 (310) 806-7239
University of California, Los Angeles
Computer Science Department
Engineering VI, Room 486
Los Angeles, CA 90095
I am a postdoctoral researcher at the Software Evolution and Analysis Laboratory (SEAL) at UCLA, working with Prof. Miryung Kim.
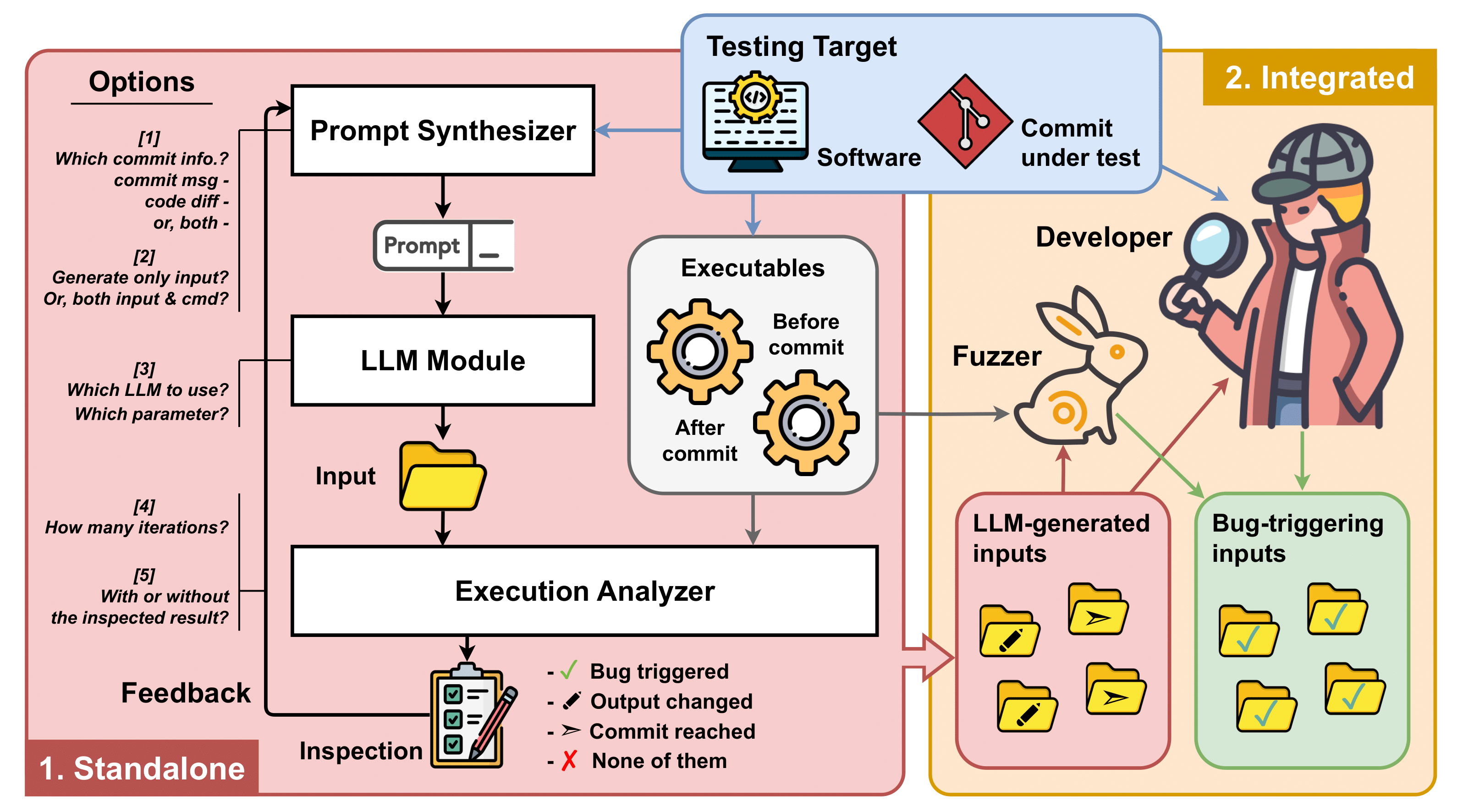
My research interests lie in program analysis and software testing, with a focus on making program analysis scalable to address the challenges associated with the scale and complexity of software systems. I aim to achieve practical software testing in real-world scenarios by utilizing statistical methods to analyze dynamic information from program execution, facilitating the reasoning of a program’s semantic properties and addressing empirical challenges in software testing.
Prior to joining SEAL, I was a postdoctoral researcher at the Max Planck Institute for Security and Privacy (MPI-SP) in Bochum, Germany, where I worked with Dr. Marcel Böhme in the Software Security group. I received my Ph.D. in Computation Intelligence and Software Engineering Lab (COINSE) at KAIST, advised by Dr. Shin Yoo in 2022.
news
| Jul, 2026 | |
|---|---|
| Jul, 2026 | |
| Jun, 2026 | |
| May, 2026 | |
| Mar, 2026 | |
selected publications (* denotes equal contribution)
2026
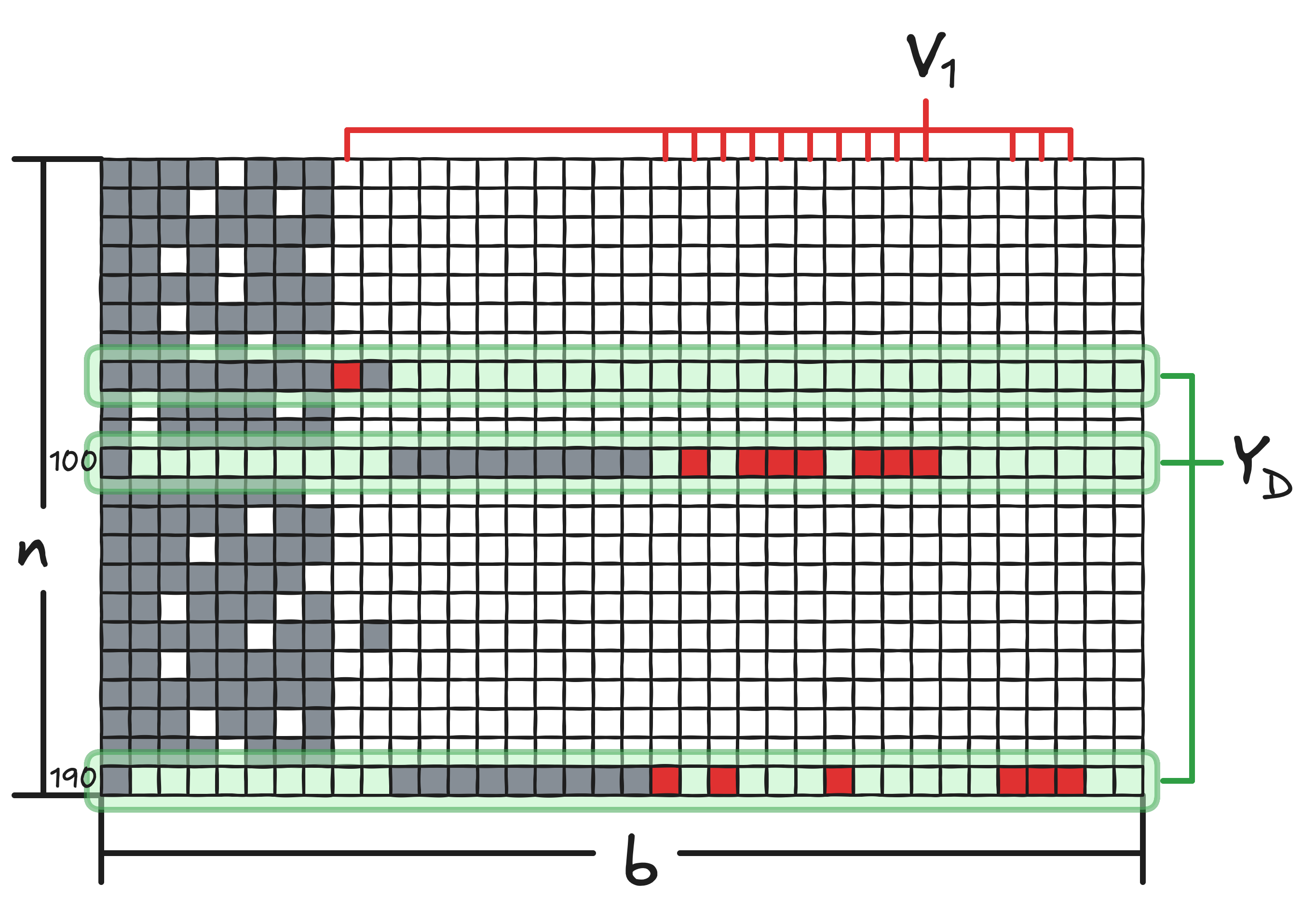
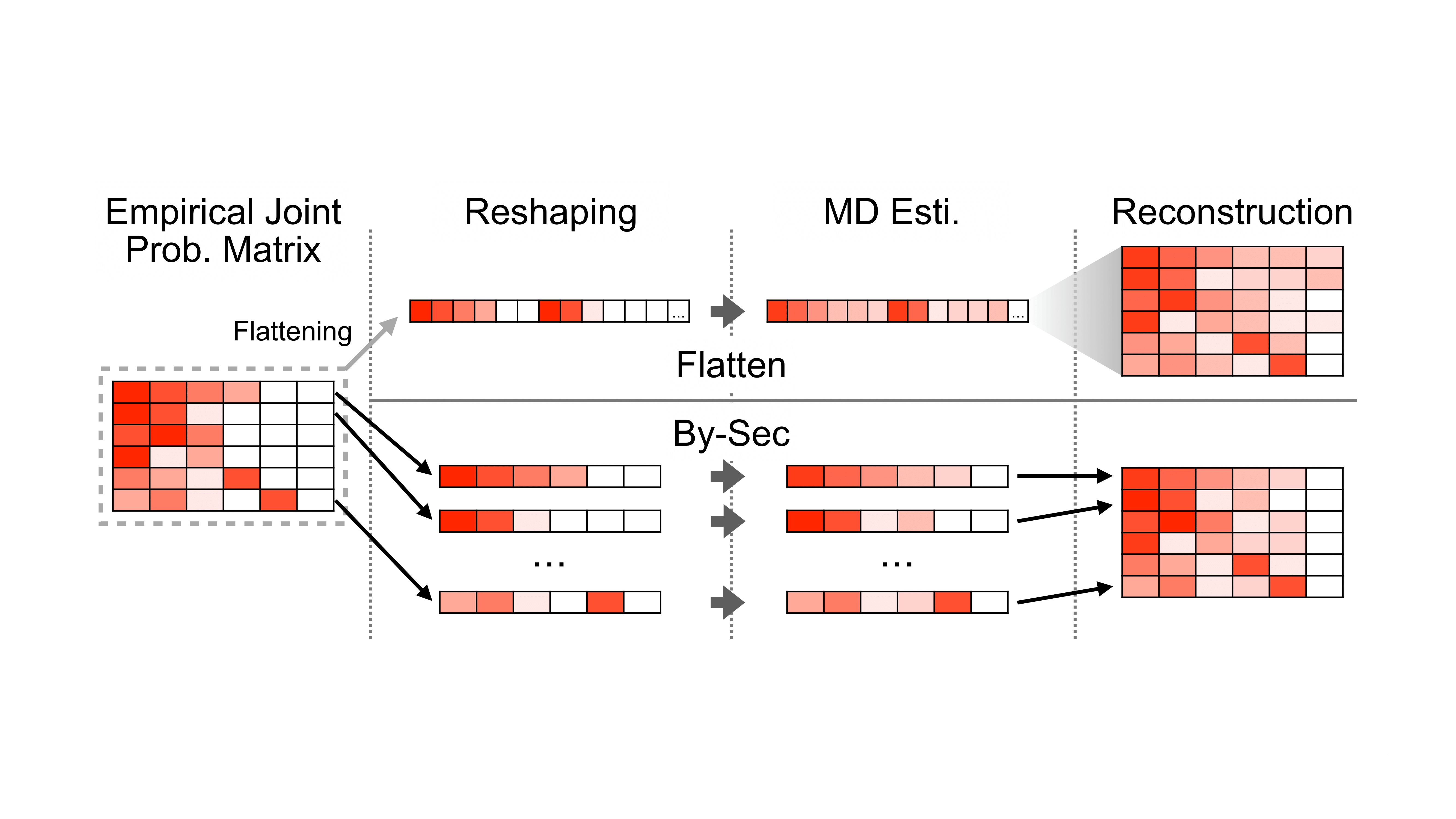
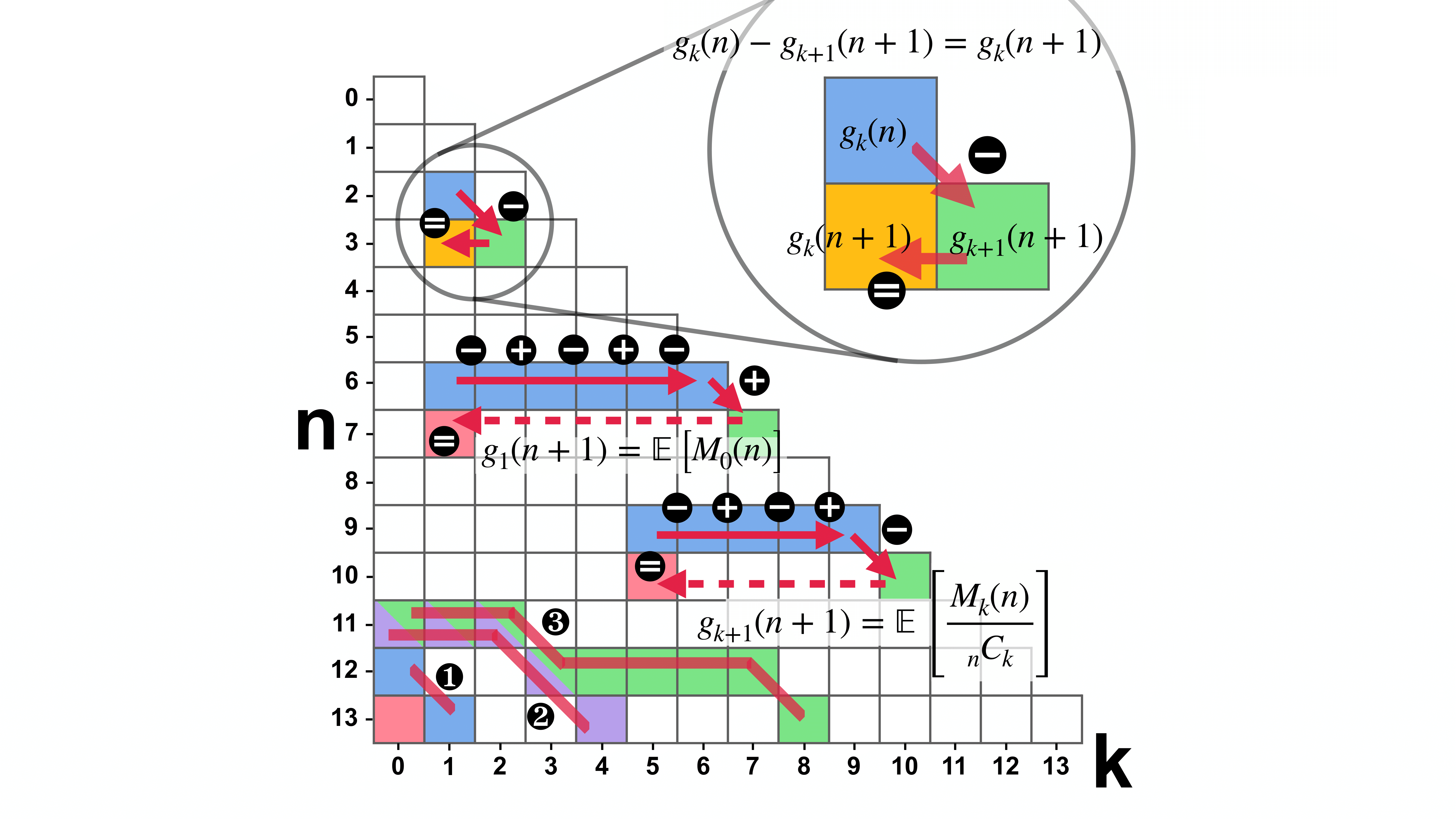
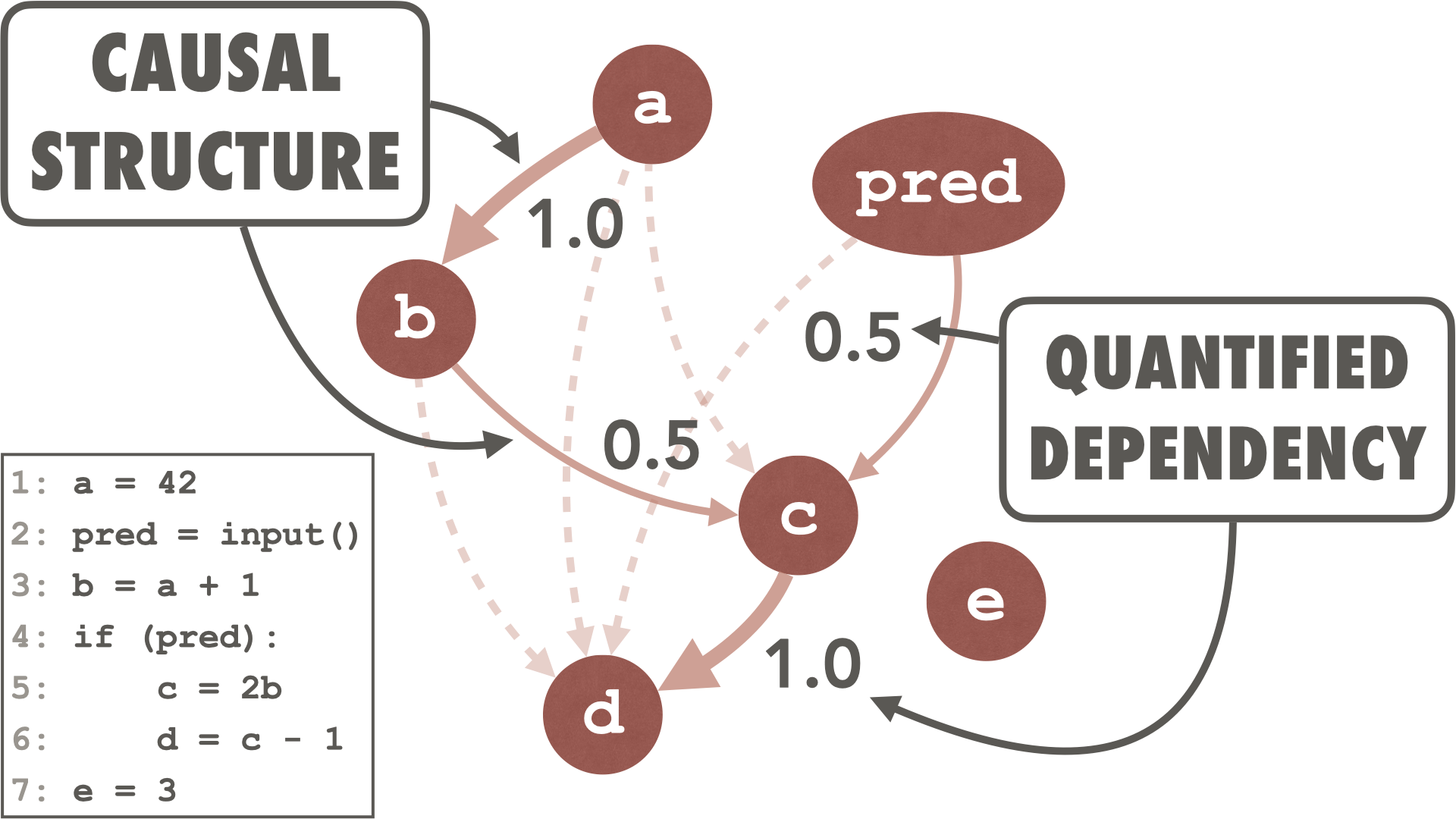
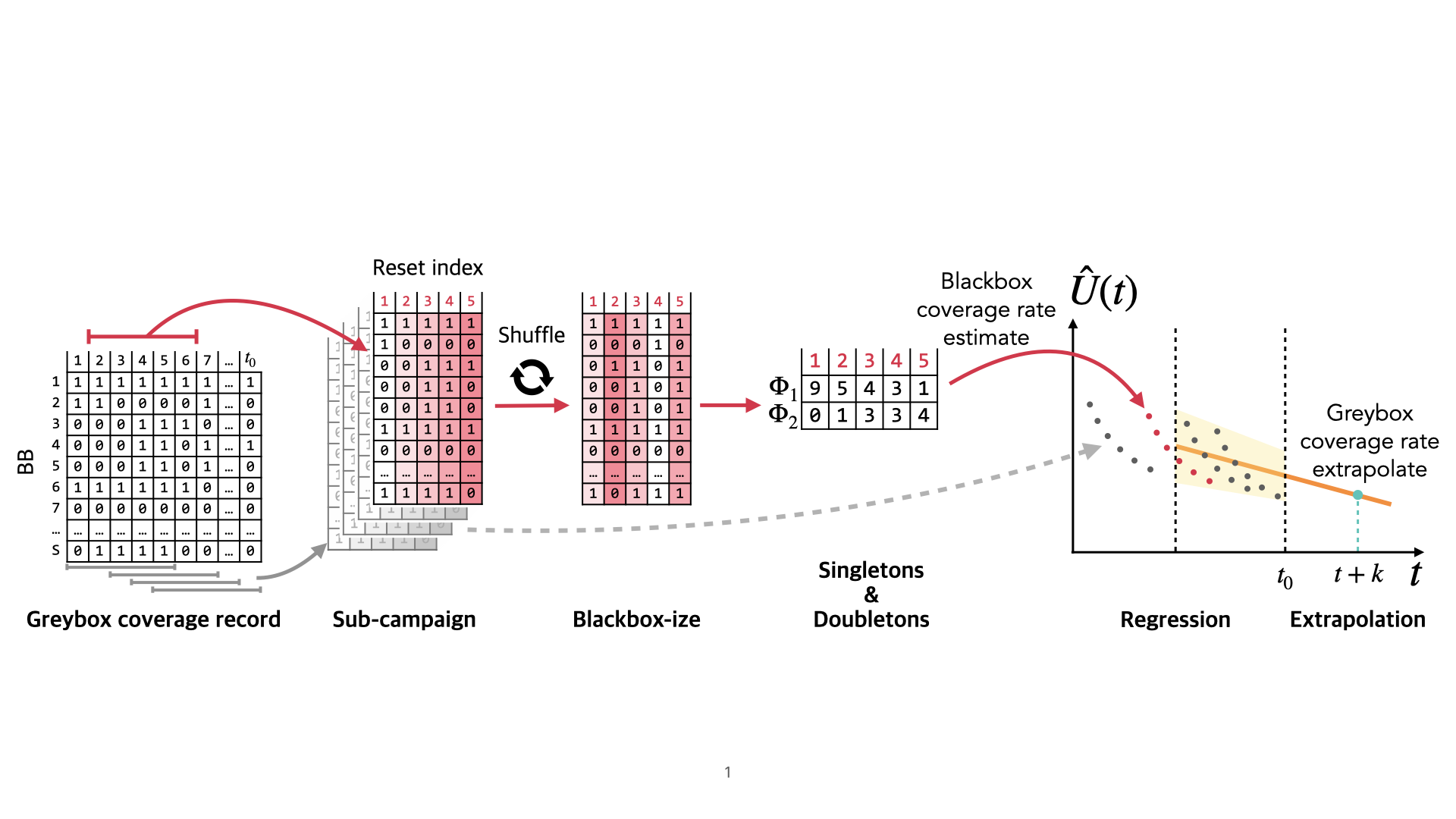
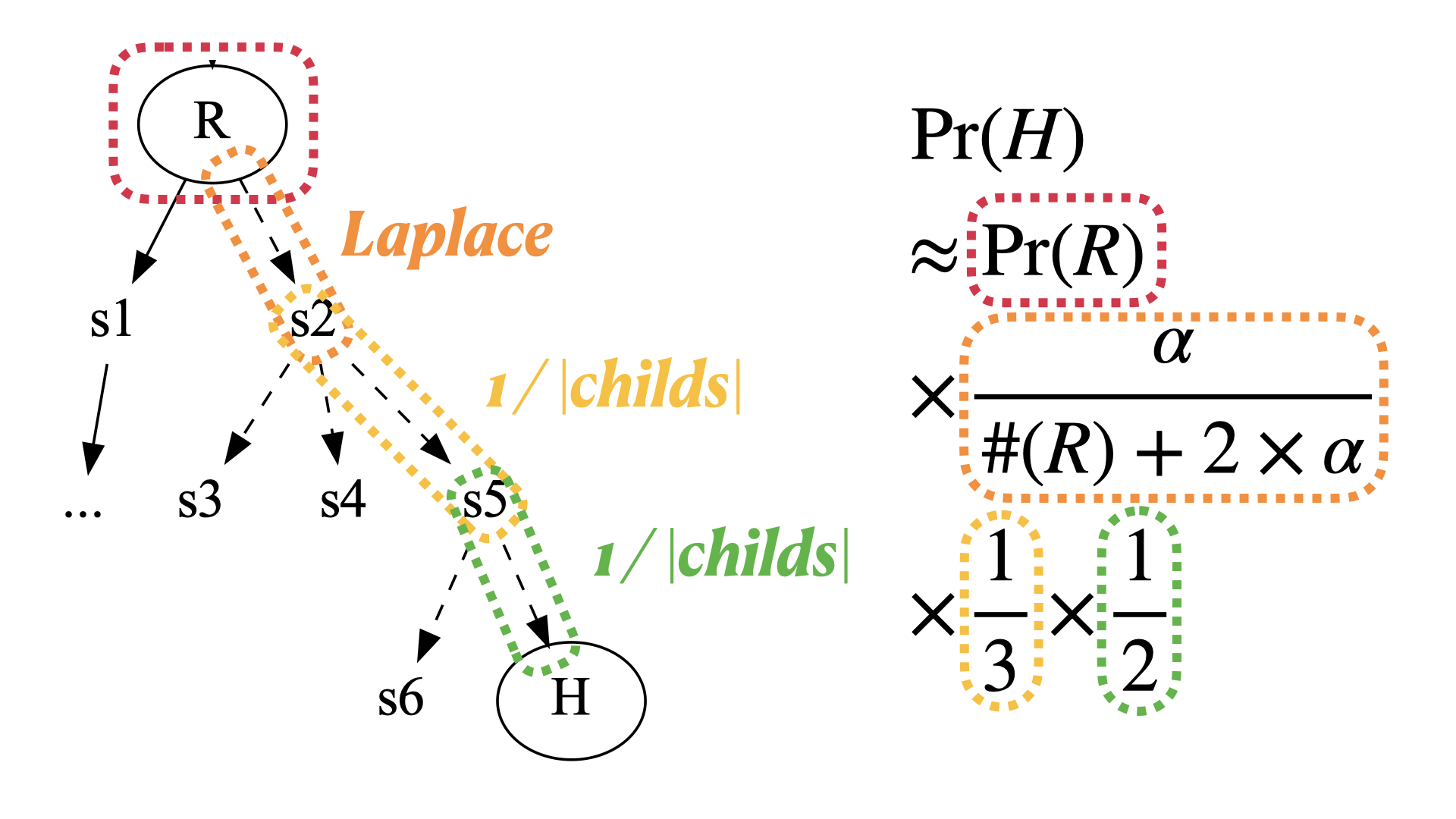
- ASEAccurate and Low-Cost Residual Risk Assessment via Sampled Profiling and Structure-Aware Coverage AmplificationIn 2026 41st IEEE/ACM International Conference on Automated Software Engineering (ASE), Oct 2026