publications
publications by categories in reversed chronological order. asterisk (*) indicates the equal contribution.
2026
- ICSEDependency-aware Residual Risk AnalysisSeongmin Lee and Marcel BöhmeIn Proceedings of the IEEE/ACM 48th International Conference on Software Engineering (ICSE’26), Apr 2026
@inproceedings{lee2025dependenceResidual, title = {Dependency-aware Residual Risk Analysis}, author = {Lee, Seongmin and B{\"o}hme, Marcel}, booktitle = {Proceedings of the {{IEEE}}/{{ACM}} 48th {{International Conference}} on {{Software Engineering}} (ICSE'26)}, year = {2026}, month = apr, selected_order = {1} } - FSEIn Bugs We Trust? On Measuring the Randomness of a Fuzzer Benchmarking OutcomeArdi Madadi, Seongmin Lee, Cornelius Aschermann, and Marcel BöhmeIn Proceedings of the ACM International Conference on the Foundations of Software Engineering, Jul 2026
@inproceedings{FSE26-concordance, title = {In Bugs We Trust? {{On}} Measuring the Randomness of a Fuzzer Benchmarking Outcome}, author = {Madadi, Ardi and Lee, Seongmin and Aschermann, Cornelius and Böhme, Marcel}, booktitle = {Proceedings of the {{ACM}} International Conference on the Foundations of Software Engineering}, year = {2026}, month = jul, selected_order = {5} } - S&PCottontail: LLM-Driven Concolic Execution for Highly Structured Test Input GenerationHaoxin Tu, Seongmin Lee, Yuxian Li, Peng Chen, Lingxiao Jiang, and Marcel BöhmeIn 2026 IEEE Symposium on Security and Privacy (S&P’26), May 2026
@inproceedings{Cottontail, title = {Cottontail: LLM-Driven Concolic Execution for Highly Structured Test Input Generation}, booktitle = {2026 {{IEEE Symposium}} on {{Security}} and {{Privacy}} ({{S\&P}}'26)}, author = {Tu, Haoxin and Lee, Seongmin and Li, Yuxian and Chen, Peng and Jiang, Lingxiao and B{\"o}hme, Marcel}, year = {2026}, month = may, publisher = {IEEE}, selected_order = {5} }
2025
- FSE-WRefining Fuzzed Crashing Inputs for Better Fault DiagnosisKieun Kim, Seongmin Lee, and Shin HongIn Proceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, New York, NY, USA, Jul 2025
We present DiffMin, a technique that refines a fuzzed crashing input to gain greater similarities to given passing inputs to help developers analyze the crashing input to identify the failure-inducing condition and locate buggy code for debugging. DiffMin iteratively applies edit actions to transform a fuzzed input while preserving the crash behavior. Our pilot study with the Magma benchmark demonstrates that DiffMin effectively minimizes the differences between crashing and passing inputs while enhancing the accuracy of spectrum-based fault localization, highlighting its potential as a valuable pre-debugging step after greybox fuzzing.
@inproceedings{kimRefiningFuzzedCrashing2025, title = {Refining {{Fuzzed Crashing Inputs}} for {{Better Fault Diagnosis}}}, booktitle = {Proceedings of the 33rd {{ACM International Conference}} on the {{Foundations}} of {{Software Engineering}}}, author = {Kim, Kieun and Lee, Seongmin and Hong, Shin}, date = {2025-07-28}, series = {{{FSE Companion}} '25}, pages = {1248--1249}, publisher = {Association for Computing Machinery}, location = {New York, NY, USA}, doi = {10.1145/3696630.3731436}, url = {https://dl.acm.org/doi/10.1145/3696630.3731436}, isbn = {979-8-4007-1276-0}, year = {2025}, month = jul, } - arXiv
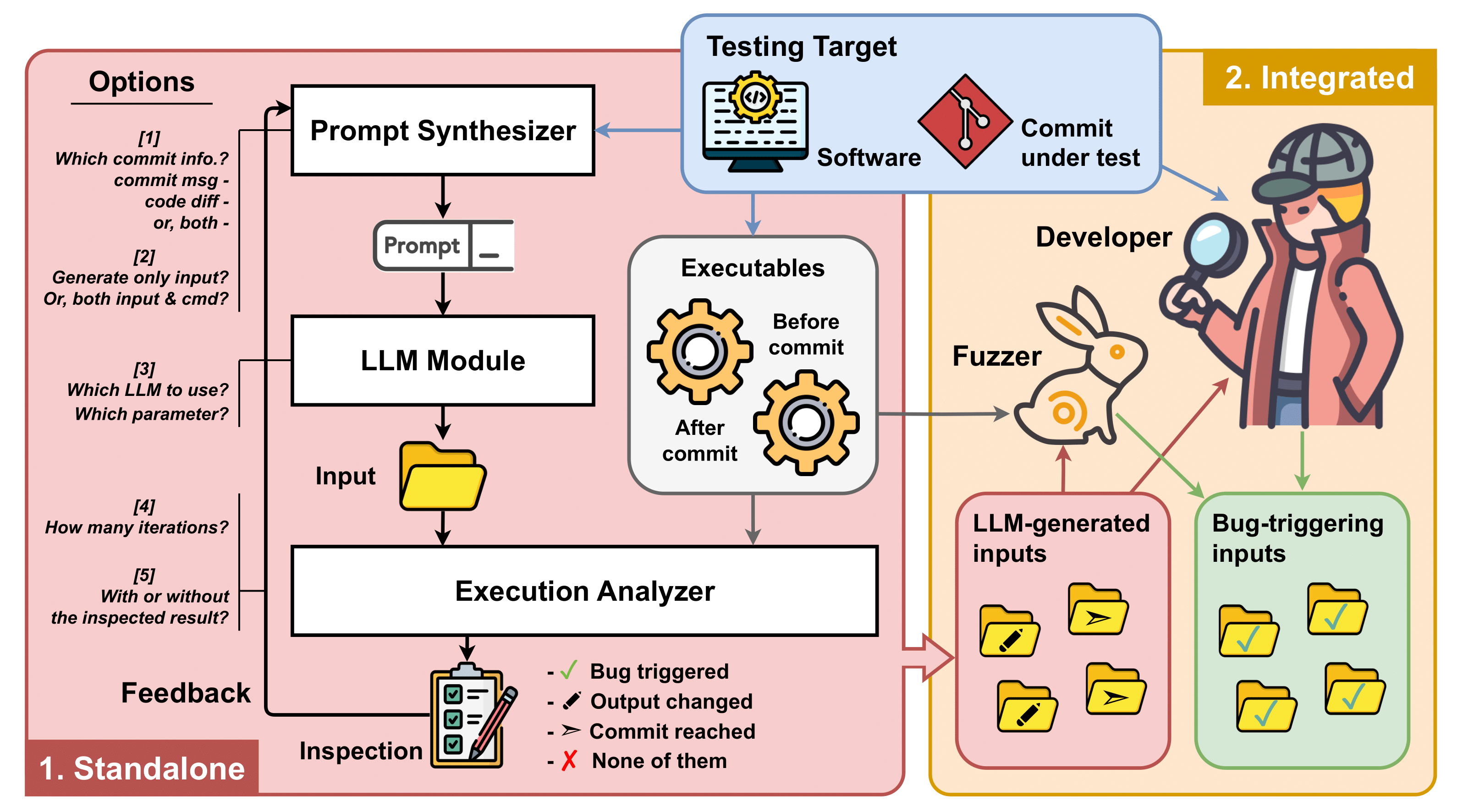 Can LLM Generate Regression Tests for Software Commits?Jing Liu*, Seongmin Lee*, Eleonora Losiouk, and Marcel BöhmeJan 2025
Can LLM Generate Regression Tests for Software Commits?Jing Liu*, Seongmin Lee*, Eleonora Losiouk, and Marcel BöhmeJan 2025@misc{liu2025llmgenerateregressiontests, title = {Can LLM Generate Regression Tests for Software Commits?}, author = {Liu, Jing and Lee, Seongmin and Losiouk, Eleonora and Böhme, Marcel}, year = {2025}, month = jan, eprint = {2501.11086}, archiveprefix = {arXiv}, primaryclass = {cs.SE}, url = {https://arxiv.org/abs/2501.11086}, } - ICSE
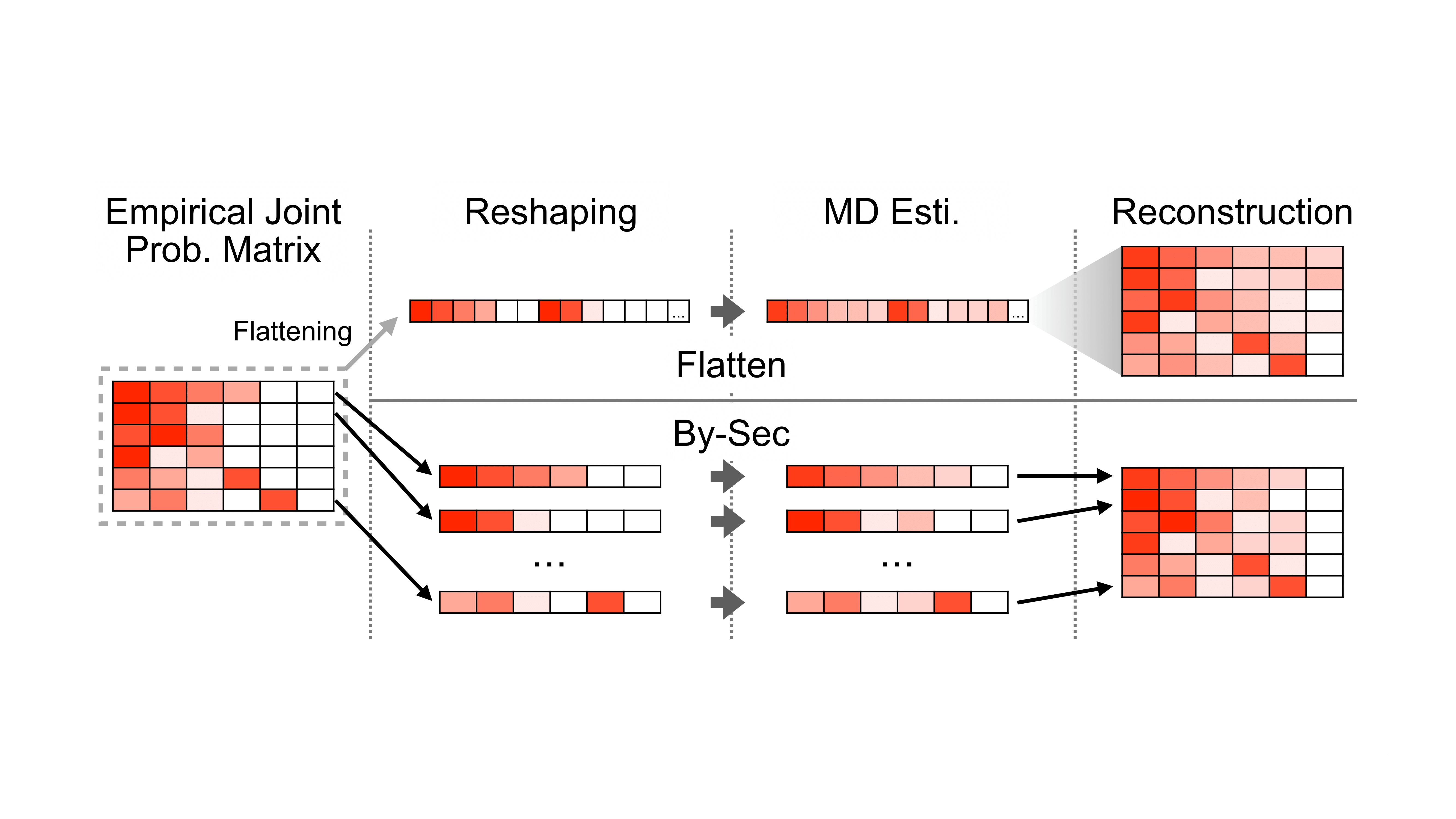 Accounting for Missing Events in Statistical Information Leakage AnalysisSeongmin Lee, Shreyas Minocha, and Marcel BöhmeIn Proceedings of the IEEE/ACM 47th International Conference on Software Engineering (ICSE’25), Jun 2025
Accounting for Missing Events in Statistical Information Leakage AnalysisSeongmin Lee, Shreyas Minocha, and Marcel BöhmeIn Proceedings of the IEEE/ACM 47th International Conference on Software Engineering (ICSE’25), Jun 2025The leakage of secret information via a public channel is a critical privacy flaw in software systems. The more information is leaked per observation, the less time an attacker needs to learn the secret. Due to the size and complexity of the modern software, and because some empirical facts are not available to a formal analysis of the source code, researchers started investigating statistical methods using program executions as samples. However, current statistical methods require a high sample coverage. Ideally, the sample is large enough to contain every possible combination of secret {}times observable value to accurately reflect the joint distribution of {}langle\secret, observable{}rangle\. Otherwise, the information leakage is severely underestimated, which is problematic as it can lead to overconfidence in the security of an otherwise vulnerable program. In this paper, we introduce an improved estimator for information leakage and propose to use methods from applied statistics to improve our estimate of the joint distribution when sample coverage is low. The key idea is to reconstruct the joint distribution by casting our problem as a multinomial estimation problem in the absence of samples for all classes. We suggest two approaches and demonstrate the effectiveness of each approach on a set of benchmark subjects. We also propose novel refinement heuristics, which help to adjust the joint distribution and gain better estimation accuracy. Compared to existing statistical methods for information leakage estimation, our method can safely overestimate the mutual information and provide a more accurate estimate from a limited number of program executions.
@inproceedings{lee2024accounting, title = {Accounting for {{Missing Events}} in {{Statistical Information Leakage Analysis}}}, booktitle = {Proceedings of the {{IEEE}}/{{ACM}} 47th {{International Conference}} on {{Software Engineering}} (ICSE'25)}, author = {Lee, Seongmin and Minocha, Shreyas and B{\"o}hme, Marcel}, year = {2025}, month = jun, publisher = {Association for Computing Machinery}, selected_order = {1} } - ICLR
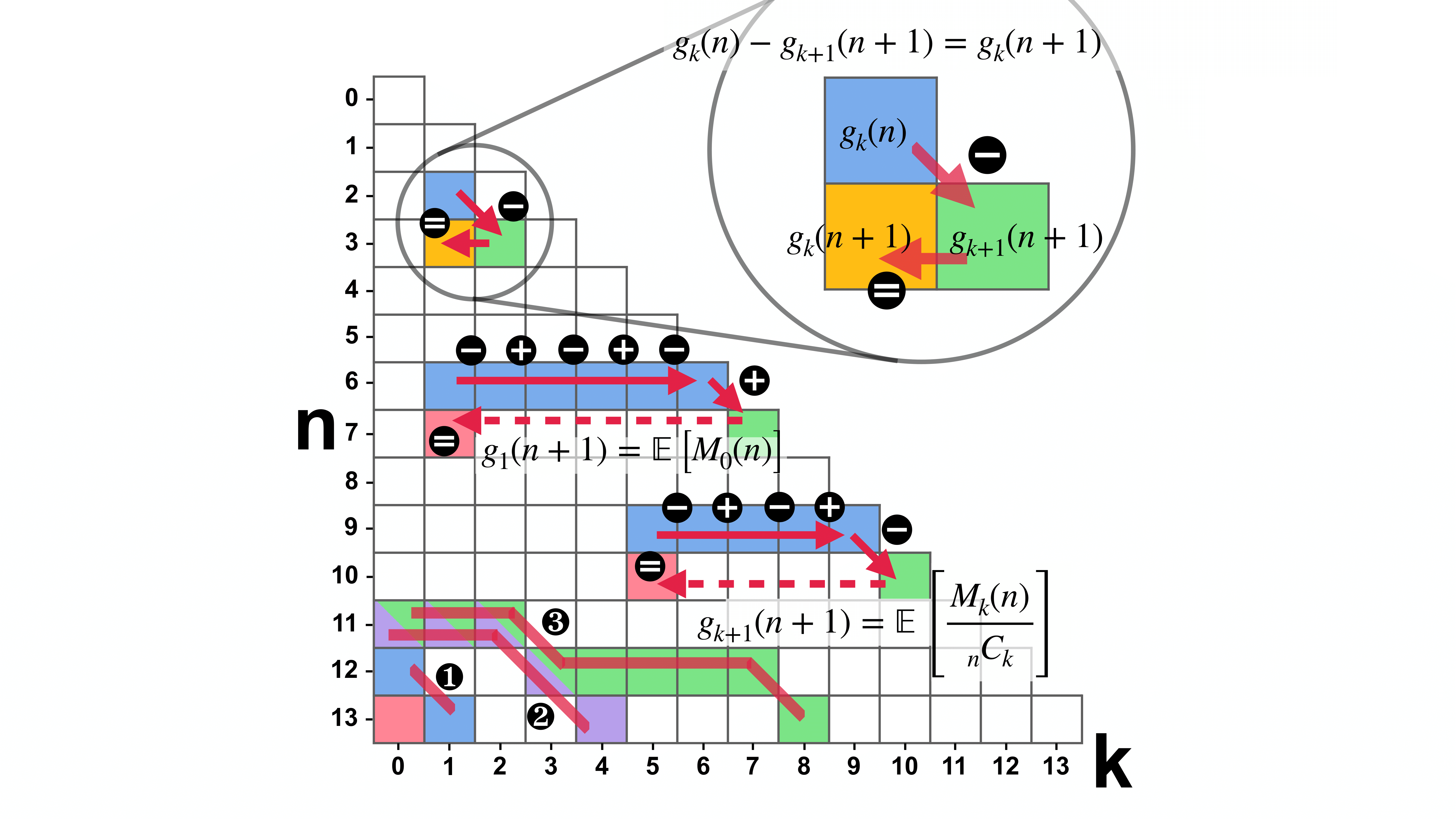 How Much Is Unseen Depends Chiefly on Information About the SeenSeongmin Lee and Marcel BöhmeIn Proceedings of the 13th International Conference on Learning Representations (ICLR’25), May 2025
How Much Is Unseen Depends Chiefly on Information About the SeenSeongmin Lee and Marcel BöhmeIn Proceedings of the 13th International Conference on Learning Representations (ICLR’25), May 2025 The paper was selected as ICLR’25 Spotlight (Top 5% of accepted papers).
The paper was selected as ICLR’25 Spotlight (Top 5% of accepted papers).The missing mass refers to the proportion of data points in an unknown population of classifier inputs that belong to classes not present in the classifier’s training data, which is assumed to be a random sample from that unknown population. We find that in expectation the missing mass is entirely determined by the number \f_k of classes that do appear in the training data the same number of times and an exponentially decaying error. While this is the first precise characterization of the expected missing mass in terms of the sample, the induced estimator suffers from an impractically high variance. However, our theory suggests a large search space of nearly unbiased estimators that can be searched effectively and efficiently. Hence, we cast distribution-free estimation as an optimization problem to find a distribution-specific estimator with a minimized mean-squared error (MSE), given only the sample. In our experiments, our search algorithm discovers estimators that have a substantially smaller MSE than the state-of-the-art Good-Turing estimator. This holds for over 93% of runs when there are at least as many samples as classes. Our estimators’ MSE is roughly 80% of the Good-Turing estimator’s.
@inproceedings{leeHowMuchUnseen2025, title = {How {{Much}} Is {{Unseen Depends Chiefly}} on {{Information About}} the {{Seen}}}, author = {Lee, Seongmin and B{\"o}hme, Marcel}, year = {2025}, month = may, booktitle = {Proceedings of the 13th International Conference on Learning Representations (ICLR'25)}, selected_order = {2} } - SCP
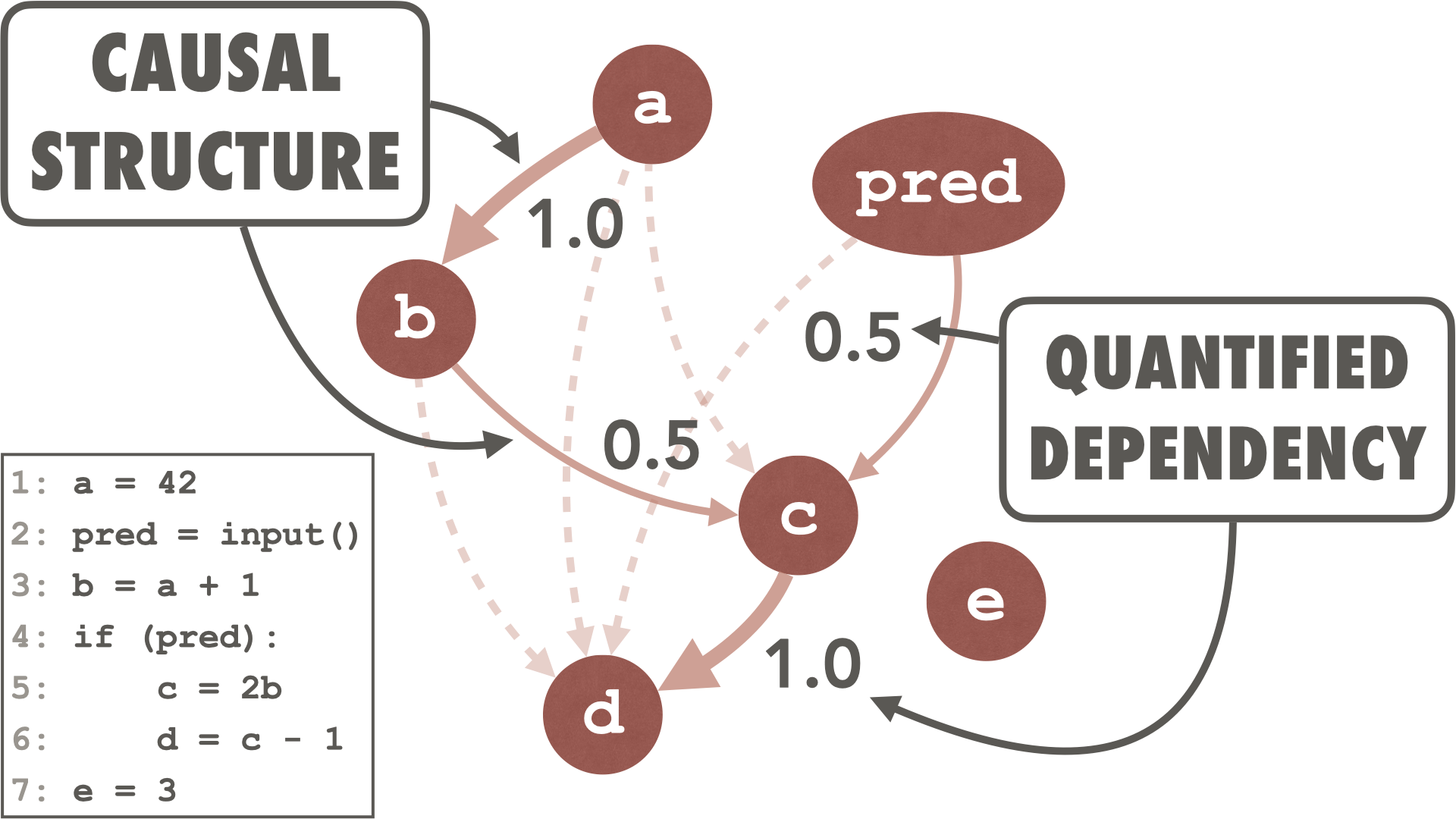 Causal Program Dependence AnalysisSeongmin Lee, Dave Binkley, Robert Feldt, Nicolas Gold, and Shin YooScience of Computer Programming, Feb 2025
Causal Program Dependence AnalysisSeongmin Lee, Dave Binkley, Robert Feldt, Nicolas Gold, and Shin YooScience of Computer Programming, Feb 2025Discovering how program components affect one another plays a fundamental role in aiding engineers comprehend and maintain a software system. Despite the fact that the degree to which one program component depends upon another can vary in strength, traditional dependence analysis typically ignores such nuance. To account for this nuance in dependence-based analysis, we propose Causal Program Dependence Analysis (CPDA), a framework based on causal inference that captures the degree (or strength) of the dependence between program elements. For a given program, CPDA intervenes in the program execution to observe changes in value at selected points in the source code. It observes the association between program elements by constructing and executing modified versions of a program (requiring only light-weight parsing rather than sophisticated static analysis). CPDA applies causal inference to the observed changes to identify and estimate the strength of the dependence relations between program elements. We explore the advantages of CPDA’s quantified dependence by presenting results for several applications. Our further qualitative evaluation demonstrates 1) that observing different levels of dependence facilitates grouping various functional aspects found in a program and 2) how focusing on the relative strength of the dependences for a particular program element provides a detailed context for that element. Furthermore, a case study that applies CPDA to debugging illustrates how it can improve engineer productivity.
@article{leeCausalProgramDependence2025, title = {Causal Program Dependence Analysis}, author = {Lee, Seongmin and Binkley, Dave and Feldt, Robert and Gold, Nicolas and Yoo, Shin}, year = {2025}, month = feb, journal = {Science of Computer Programming}, volume = {240}, pages = {103208}, issn = {0167-6423}, doi = {10.1016/j.scico.2024.103208}, selected_order = {6} }
2024
- ICSE
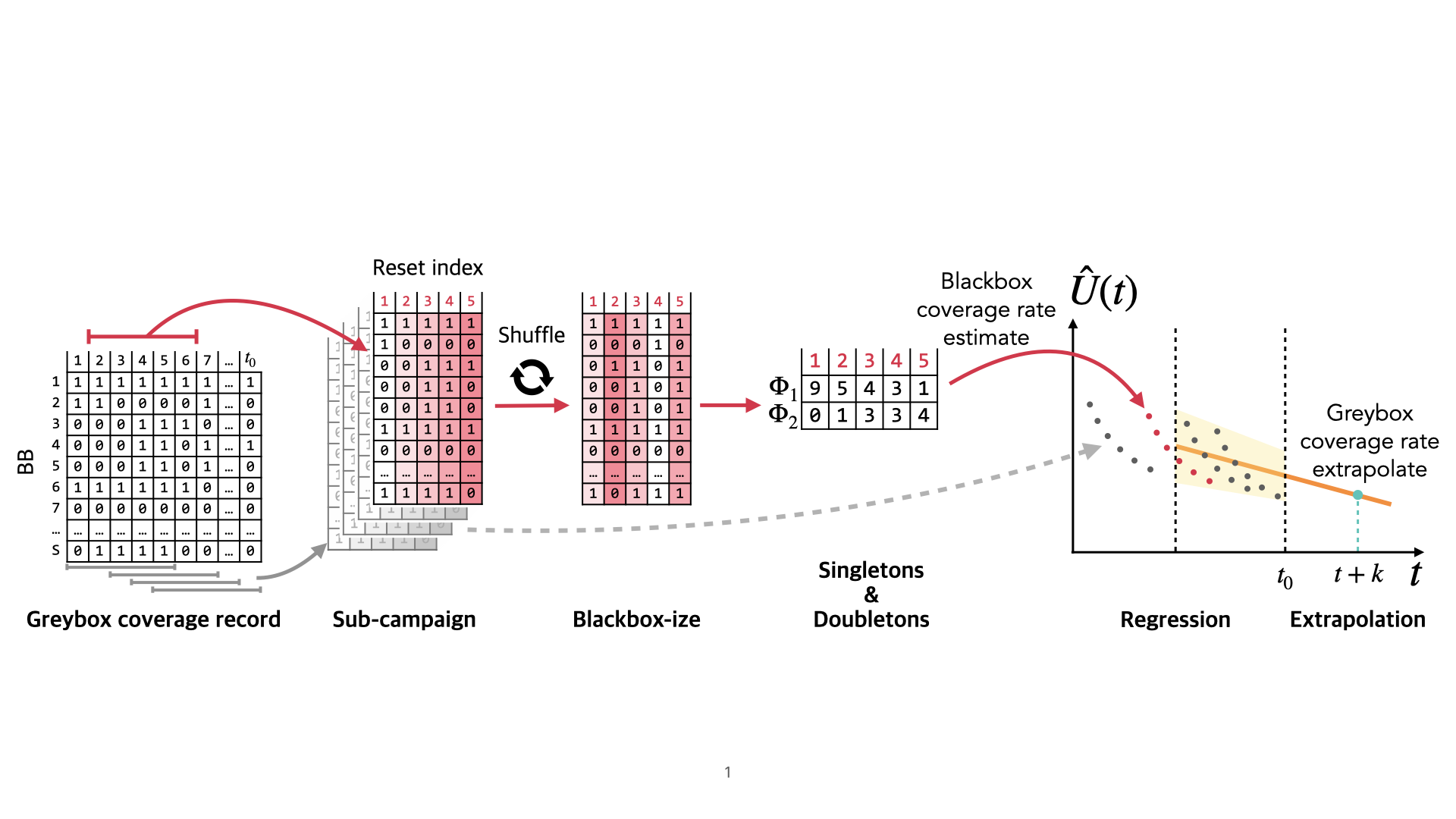 Extrapolating Coverage Rate in Greybox FuzzingDanushka Liyanage*, Seongmin Lee*, Chakkrit Tantithamthavorn, and Marcel BöhmeIn Proceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE’24), Apr 2024
Extrapolating Coverage Rate in Greybox FuzzingDanushka Liyanage*, Seongmin Lee*, Chakkrit Tantithamthavorn, and Marcel BöhmeIn Proceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE’24), Apr 2024A fuzzer can literally run forever. However, as more resources are spent, the coverage rate continuously drops, and the utility of the fuzzer declines. To tackle this coverage-resource tradeoff, we could introduce a policy to stop a campaign whenever the coverage rate drops below a certain threshold value, say 10 new branches covered per 15 minutes. During the campaign, can we predict the coverage rate at some point in the future? If so, how well can we predict the future coverage rate as the prediction horizon or the current campaign length increases? How can we tackle the statistical challenge of adaptive bias, which is inherent in greybox fuzzing (i.e., samples are not independent and identically distributed)?In this paper, we i) evaluate existing statistical techniques to predict the coverage rate U(t0 + k) at any time t0 in the campaign after a period of k units of time in the future and ii) develop a new extrapolation methodology that tackles the adaptive bias. We propose to efficiently simulate a large number of blackbox campaigns from the collected coverage data, estimate the coverage rate for each of these blackbox campaigns and conduct a simple regression to extrapolate the coverage rate for the greybox campaign.Our empirical evaluation using the Fuzztastic fuzzer benchmark demonstrates that our extrapolation methodology exhibits at least one order of magnitude lower error compared to the existing benchmark for 4 out of 5 experimental subjects we investigated. Notably, compared to the existing extrapolation methodology, our extrapolator excels in making long-term predictions, such as those extending up to three times the length of the current campaign.
@inproceedings{liyanageExtrapolatingCoverageRate2024, title = {Extrapolating {{Coverage Rate}} in {{Greybox Fuzzing}}}, booktitle = {Proceedings of the {{IEEE}}/{{ACM}} 46th {{International Conference}} on {{Software Engineering}} ({{ICSE}}'24)}, author = {Liyanage, Danushka and Lee, Seongmin and Tantithamthavorn, Chakkrit and B{\"o}hme, Marcel}, year = {2024}, month = apr, series = {{{ICSE}} '24}, pages = {1--12}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {10.1145/3597503.3639198}, isbn = {9798400702174}, selected_order = {3} }
2023
- ESEC/FSE
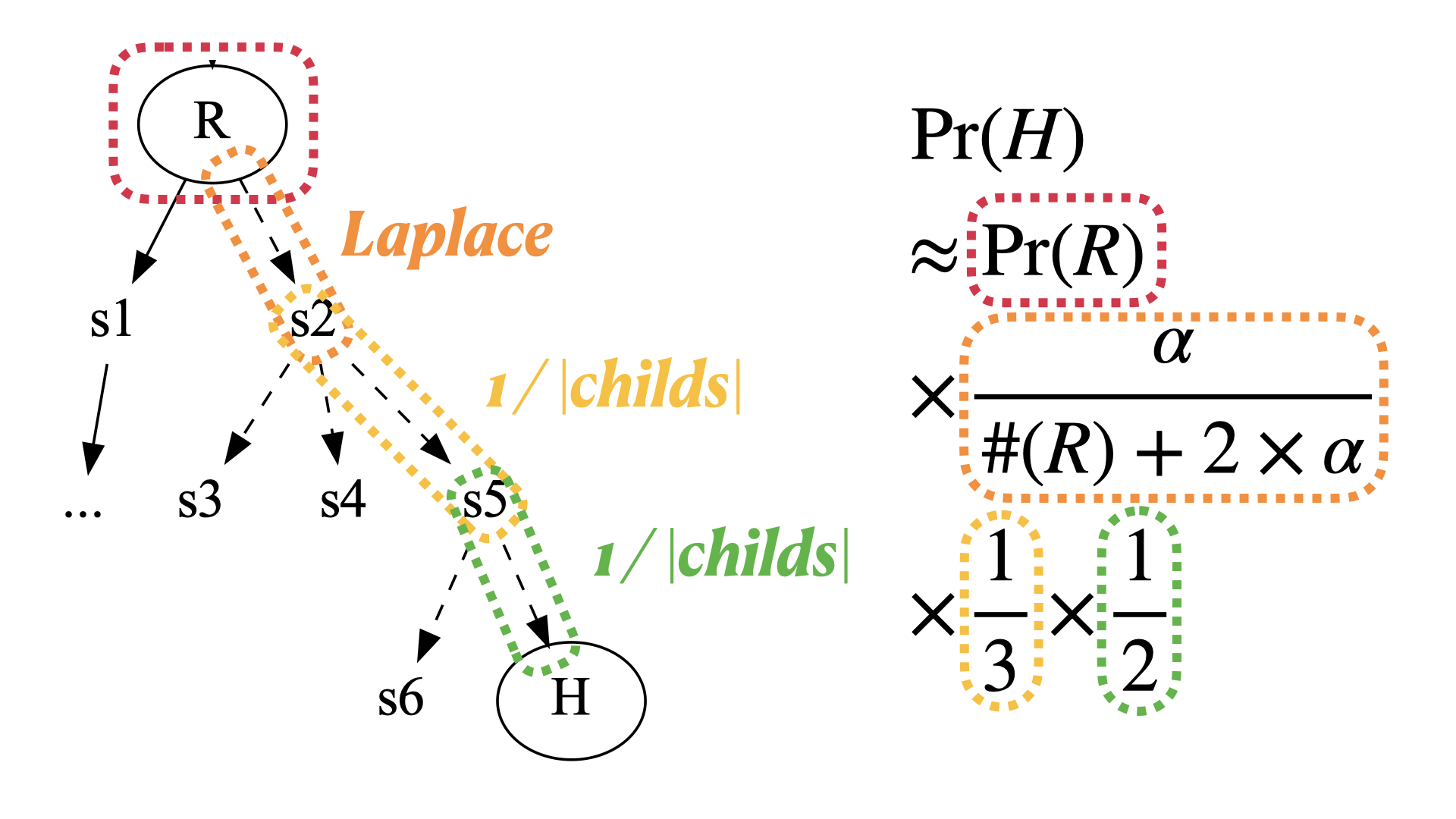 Statistical Reachability AnalysisSeongmin Lee and Marcel BöhmeIn Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE’23), Nov 2023
Statistical Reachability AnalysisSeongmin Lee and Marcel BöhmeIn Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE’23), Nov 2023Given a target program state (or statement) s, what is the probability that an input reaches s? This is the quantitative reachability analysis problem. For instance, quantitative reachability analysis can be used to approximate the reliability of a program (where s is a bad state). Traditionally, quantitative reachability analysis is solved as a model counting problem for a formal constraint that represents the (approximate) reachability of s along paths in the program, i.e., probabilistic reachability analysis. However, in preliminary experiments, we failed to run state-of-the-art probabilistic reachability analysis on reasonably large programs. In this paper, we explore statistical methods to estimate reachability probability. An advantage of statistical reasoning is that the size and composition of the program are insubstantial as long as the program can be executed. We are particularly interested in the error compared to the state-of-the-art probabilistic reachability analysis. We realize that existing estimators do not exploit the inherent structure of the program and develop structure-aware estimators to further reduce the estimation error given the same number of samples. Our empirical evaluation on previous and new benchmark programs shows that (i) our statistical reachability analysis outperforms state-of-the-art probabilistic reachability analysis tools in terms of accuracy, efficiency, and scalability, and (ii) our structure-aware estimators further outperform (blackbox) estimators that do not exploit the inherent program structure. We also identify multiple program properties that limit the applicability of the existing probabilistic analysis techniques.
@inproceedings{leeStatisticalReachabilityAnalysis2023, title = {Statistical {{Reachability Analysis}}}, booktitle = {Proceedings of the 31st {{ACM Joint European Software Engineering Conference}} and {{Symposium}} on the {{Foundations}} of {{Software Engineering}} ({{ESEC}}/{{FSE}}'23)}, author = {Lee, Seongmin and B{\"o}hme, Marcel}, year = {2023}, month = nov, series = {{{ESEC}}/{{FSE}} 2023}, pages = {326--337}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {10.1145/3611643.3616268}, isbn = {9798400703270}, selected_order = {4} }
2022
- PhD ThesisStatistical Program Dependence ApproximationSeongmin LeeKorea Advanced Institute of Science and Technology (KAIST), Daejeon, Jun 2022
@phdthesis{leeStatisticalProgramDependence2022, title = {Statistical Program Dependence Approximation}, author = {Lee, Seongmin}, year = {2022}, month = jun, school = {Korea Advanced Institute of Science and Technology (KAIST), Daejeon}, }
2021
- JSS
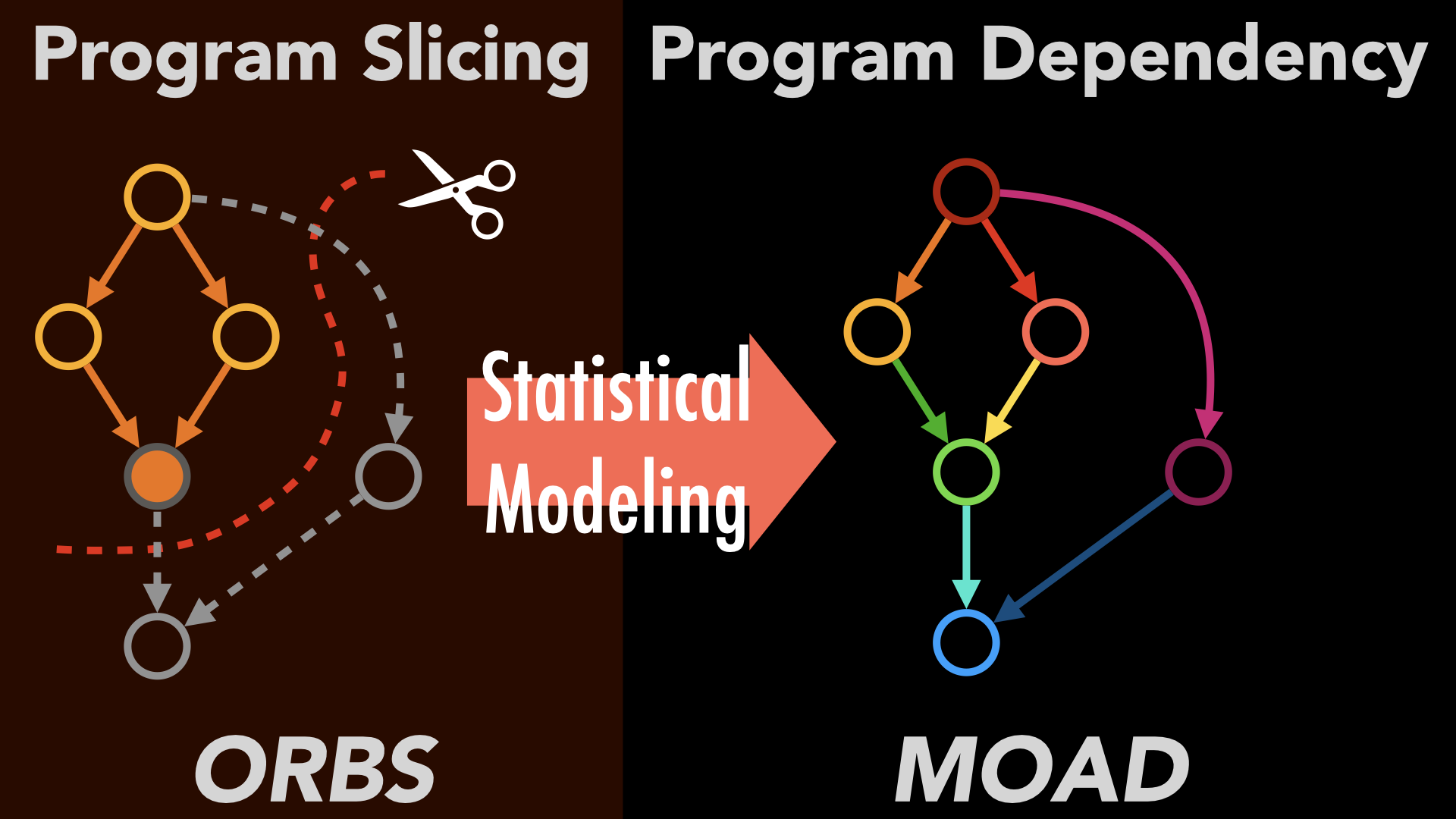 Observation-Based Approximate Dependency Modeling and Its Use for Program SlicingSeongmin Lee, David Binkley, Robert Feldt, Nicolas Gold, and Shin YooJournal of Systems and Software, Sep 2021
Observation-Based Approximate Dependency Modeling and Its Use for Program SlicingSeongmin Lee, David Binkley, Robert Feldt, Nicolas Gold, and Shin YooJournal of Systems and Software, Sep 2021While dependency analysis is foundational to much program analysis, many techniques have limited scalability and handle only monolingual systems. We present a novel dependency analysis technique that aims to approximate program dependency from a relatively small number of perturbed executions. Our technique, MOAD (Modeling Observation-based Approximate Dependency), reformulates program dependency as the likelihood that one program element is dependent on another (instead of a Boolean relationship). MOAD generates program variants by deleting parts of the source code and executing them while observing the impact. MOAD thus infers a model of program dependency that captures the relationship between the modification and observation points. We evaluate MOAD using program slices obtained from the resulting probabilistic dependency models. Compared to the existing observation-based backward slicing technique, ORBS, MOAD requires only 18.6% of the observations, while the resulting slices are only 12% larger on average. Furthermore, we introduce the notion of the observation-based forward slices. Unlike ORBS, which inherently computes backward slices, MOAD’s model’s dependences can be traversed in either direction allowing us to easily compute forward slices. In comparison to the static forward slice, MOAD only misses deleting 0–6 lines (median 0), while excessively deleting 0–37 lines (median 8) from the slice.
@article{leeObservationbasedApproximateDependency2021, title = {Observation-Based Approximate Dependency Modeling and Its Use for Program Slicing}, author = {Lee, Seongmin and Binkley, David and Feldt, Robert and Gold, Nicolas and Yoo, Shin}, year = {2021}, month = sep, journal = {Journal of Systems and Software}, volume = {179}, pages = {110988}, issn = {0164-1212}, doi = {10.1016/j.jss.2021.110988}, } - MutationEffectively Sampling Higher Order Mutants Using Causal EffectSaeyoon Oh, Seongmin Lee, and Shin YooIn 2021 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Apr 2021
Higher Order Mutation (HOM) has been proposed to avoid equivalent mutants and improve the scalability of mutation testing, but generating useful HOMs remain an expensive search problem on its own. We propose a new approach to generate Strongly Subsuming Higher Order Mutants (SSHOM) using a recently introduced Causal Program Dependence Analysis (CPDA). CPDA itself is based on program mutation, and provides quantitative estimation of how often a change of the value of a program element will cause a value change of another program element. Our SSHOM generation approach chooses pairs of program elements using heuristics based on CPDA analysis, performs First Order Mutation to the chosen pairs, and generates an HOM by combining two FOMs.
@inproceedings{ohEffectivelySamplingHigher2021, title = {Effectively {{Sampling Higher Order Mutants Using Causal Effect}}}, booktitle = {2021 {{IEEE International Conference}} on {{Software Testing}}, {{Verification}} and {{Validation Workshops}} ({{ICSTW}})}, author = {Oh, Saeyoon and Lee, Seongmin and Yoo, Shin}, year = {2021}, month = apr, pages = {19--24}, doi = {10.1109/ICSTW52544.2021.00017}, }
2020
- ICSE-WScalable and Approximate Program Dependence AnalysisSeongmin LeeIn Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering: Companion Proceedings, Oct 2020
Program dependence is a fundamental concept to many software engineering tasks, yet the traditional dependence analysis struggles to cope with common modern development practices such as multi-lingual implementations and use of third-party libraries. While Observation-based Slicing (ORBS) solves these issues and produces an accurate slice, it has a scalability problem due to the need to build and execute the target program multiple times. We would like to propose a radical change of perspective: a useful dependence analysis needs to be scalable even if it approximates the dependency. Our goal is a scalable approximate program dependence analysis via estimating the likelihood of dependence. We claim that 1) using external information such as lexical analysis or a development history, 2) learning dependence model from partial observations, and 3) merging static, and observation-based approach would assist the proposition. We expect that our technique would introduce a new perspective of program dependence analysis into the likelihood of dependence. It would also broaden the capability of the dependence analysis towards large and complex software.
@inproceedings{leeScalableApproximateProgram2020, title = {Scalable and Approximate Program Dependence Analysis}, booktitle = {Proceedings of the {{ACM}}/{{IEEE}} 42nd {{International Conference}} on {{Software Engineering}}: {{Companion Proceedings}}}, author = {Lee, Seongmin}, year = {2020}, month = oct, series = {{{ICSE}} '20}, pages = {162--165}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {10.1145/3377812.3381392}, isbn = {978-1-4503-7122-3}, } - Soft. Eng. NotesGenetic Improvement @ ICSE 2020William B. Langdon, Westley Weimer, Justyna Petke, Erik Fredericks, Seongmin Lee, Emily Winter, and 10 more authorsSIGSOFT Softw. Eng. Notes, Oct 2020
Following Prof. Mark Harman of Facebook’s keynote and formal presentations (which are recorded in the proceed- ings) there was a wide ranging discussion at the eighth inter- national Genetic Improvement workshop, GI-2020 @ ICSE (held as part of the International Conference on Software En- gineering on Friday 3rd July 2020). Topics included industry take up, human factors, explainabiloity (explainability, jus- tifyability, exploitability) and GI benchmarks. We also con- trast various recent online approaches (e.g. SBST 2020) to holding virtual computer science conferences and workshops via the WWW on the Internet without face to face interac- tion. Finally we speculate on how the Coronavirus Covid-19 Pandemic will a ect research next year and into the future.
@article{langdonGeneticImprovementICSE2020, title = {Genetic {{Improvement}} @ {{ICSE}} 2020}, author = {Langdon, William B. and Weimer, Westley and Petke, Justyna and Fredericks, Erik and Lee, Seongmin and Winter, Emily and Basios, Michail and Cohen, Myra B. and Blot, Aymeric and Wagner, Markus and Bruce, Bobby R. and Yoo, Shin and Gerasimou, Simos and Krauss, Oliver and Huang, Yu and Gerten, Michael}, year = {2020}, month = oct, journal = {SIGSOFT Softw. Eng. Notes}, volume = {45}, number = {4}, pages = {24--30}, issn = {0163-5948}, doi = {10.1145/3417564.3417575}, } - JSS
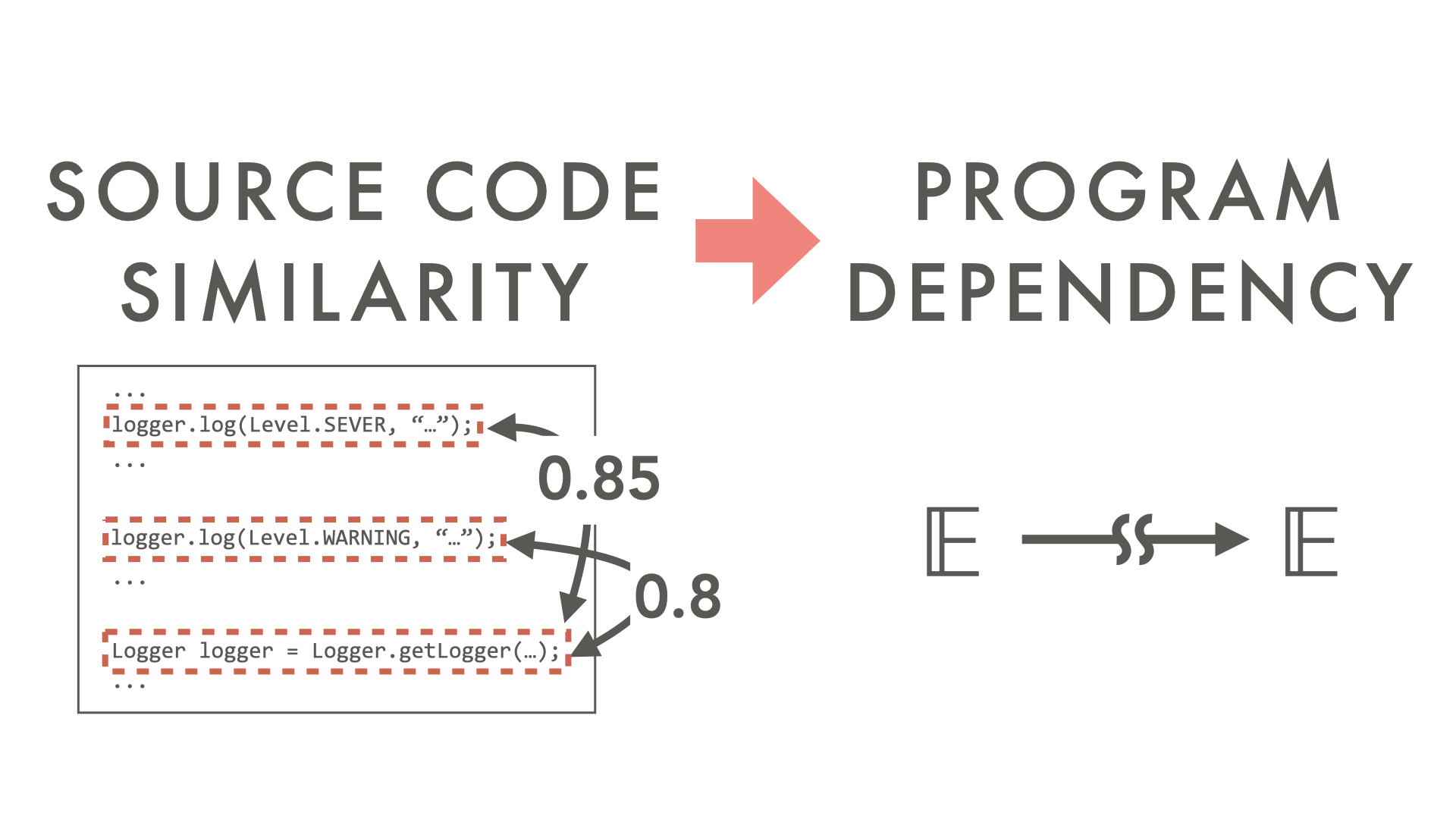 Evaluating Lexical Approximation of Program DependenceSeongmin Lee, David Binkley, Nicolas Gold, Syed Islam, Jens Krinke, and Shin YooJournal of Systems and Software, Feb 2020
Evaluating Lexical Approximation of Program DependenceSeongmin Lee, David Binkley, Nicolas Gold, Syed Islam, Jens Krinke, and Shin YooJournal of Systems and Software, Feb 2020Complex dependence analysis typically provides an underpinning approximation of true program dependence. We investigate the effectiveness of using lexical information to approximate such dependence, introducing two new deletion operators to Observation-Based Slicing (ORBS). ORBS provides direct observation of program dependence, computing a slice using iterative, speculative deletion of program parts. Deletions become permanent if they do not affect the slicing criterion. The original ORBS uses a bounded deletion window operator that attempts to delete consecutive lines together. Our new deletion operators attempt to delete multiple, non-contiguous lines that are lexically similar to each other. We evaluate the lexical dependence approximation by exploring the trade-off between the precision and the speed of dependence analysis performed with new deletion operators. The deletion operators are evaluated independently, as well as collectively via a novel generalization of ORBS that exploits multiple deletion operators: Multi-operator Observation-Based Slicing (MOBS). An empirical evaluation using three Java projects, six C projects, and one multi-lingual project written in Python and C finds that the lexical information provides a useful approximation to the underlying dependence. On average, MOBS can delete 69% of lines deleted by the original ORBS, while taking only 36% of the wall clock time required by ORBS.
@article{leeEvaluatingLexicalApproximation2020, title = {Evaluating Lexical Approximation of Program Dependence}, author = {Lee, Seongmin and Binkley, David and Gold, Nicolas and Islam, Syed and Krinke, Jens and Yoo, Shin}, year = {2020}, month = feb, journal = {Journal of Systems and Software}, volume = {160}, pages = {110459}, issn = {0164-1212}, doi = {10.1016/j.jss.2019.110459}, }
2019
- SCAMMOAD: Modeling Observation-Based Approximate DependencySeongmin Lee, David Binkley, Robert Feldt, Nicolas Gold, and Shin YooIn 2019 19th International Working Conference on Source Code Analysis and Manipulation (SCAM’19), Sep 2019
While dependency analysis is foundational to many applications of program analysis, the static nature of many existing techniques presents challenges such as limited scalability and inability to cope with multi-lingual systems. We present a novel dependency analysis technique that aims to approximate program dependency from a relatively small number of perturbed executions. Our technique, called MOAD (Modeling Observation-based Approximate Dependency), reformulates program dependency as the likelihood that one program element is dependent on another, instead of a more classical Boolean relationship. MOAD generates a set of program variants by deleting parts of the source code, and executes them while observing the impacts of the deletions on various program points. From these observations, MOAD infers a model of program dependency that captures the dependency relationship between the modification and observation points. While MOAD is a purely dynamic dependency analysis technique similar to Observation Based Slicing (ORBS), it does not require iterative deletions. Rather, MOAD makes a much smaller number of multiple, independent observations in parallel and infers dependency relationships for multiple program elements simultaneously, significantly reducing the cost of dynamic dependency analysis. We evaluate MOAD by instantiating program slices from the obtained probabilistic dependency model. Compared to ORBS, MOAD’s model construction requires only 18.7% of the observations used by ORBS, while its slices are only 16% larger than the corresponding ORBS slice, on average.
@inproceedings{leeMOADModelingObservationBased2019, title = {{{MOAD}}: {{Modeling Observation-Based Approximate Dependency}}}, shorttitle = {{{MOAD}}}, booktitle = {2019 19th {{International Working Conference}} on {{Source Code Analysis}} and {{Manipulation}} ({{SCAM'19}})}, author = {Lee, Seongmin and Binkley, David and Feldt, Robert and Gold, Nicolas and Yoo, Shin}, year = {2019}, month = sep, pages = {12--22}, issn = {2470-6892}, doi = {10.1109/SCAM.2019.00011}, } - ICSTClassifying False Positive Static Checker Alarms in Continuous Integration Using Convolutional Neural NetworksSeongmin Lee, Shin Hong, Jungbae Yi, Taeksu Kim, Chul-Joo Kim, and Shin YooIn 2019 12th IEEE Conference on Software Testing, Validation and Verification (ICST’19), Apr 2019
Static code analysis in Continuous Integration (CI) environment can significantly improve the quality of a software system because it enables early detection of defects without any test executions or user interactions. However, being a conservative over-approximation of system behaviours, static analysis also produces a large number of false positive alarms, identification of which takes up valuable developer time. We present an automated classifier based on Convolutional Neural Networks (CNNs). We hypothesise that many false positive alarms can be classified by identifying specific lexical patterns in the parts of the code that raised the alarm: human engineers adopt a similar tactic. We train a CNN based classifier to learn and detect these lexical patterns, using a total of about 10K historical static analysis alarms generated by six static analysis checkers for over 27 million LOC, and their labels assigned by actual developers. The results of our empirical evaluation suggest that our classifier can be highly effective for identifying false positive alarms, with the average precision across all six checkers of 79.72%.
@inproceedings{leeClassifyingFalsePositive2019, title = {Classifying {{False Positive Static Checker Alarms}} in {{Continuous Integration Using Convolutional Neural Networks}}}, booktitle = {2019 12th {{IEEE Conference}} on {{Software Testing}}, {{Validation}} and {{Verification}} ({{ICST'19}})}, author = {Lee, Seongmin and Hong, Shin and Yi, Jungbae and Kim, Taeksu and Kim, Chul-Joo and Yoo, Shin}, year = {2019}, month = apr, pages = {391--401}, issn = {2159-4848}, doi = {10.1109/ICST.2019.00048}, }
2018
- ICSE-WMOBS: Multi-Operator Observation-Based Slicing Using Lexical Approximation of Program DependenceSeongmin Lee, David Binkley, Nicolas Gold, Syed Islam, Jens Krinke, and Shin YooIn Proceedings of the 40th International Conference on Software Engineering: Companion Proceeedings, May 2018
Observation-Based Slicing (ORBS) is a recently introduced program slicing technique based on direct observation of program semantics. Previous ORBS implementations slice a program by iteratively deleting adjacent lines of code. This paper introduces two new deletion operators based on lexical similarity. Furthermore, it presents a generalization of O RBS that can exploit multiple deletion operators: Multi-operator Observation-Based Slicing (MOBS). An empirical evaluation of MOBS using three real world Java projects finds that the use of lexical information, improves the efficiency of ORBS: MOBS can delete up to 87% of lines while taking only about 33% of the execution time with respect to the original ORBS.
@inproceedings{leeMOBSMultioperatorObservationbased2018, title = {{{MOBS}}: Multi-Operator Observation-Based Slicing Using Lexical Approximation of Program Dependence}, shorttitle = {{{MOBS}}}, booktitle = {Proceedings of the 40th {{International Conference}} on {{Software Engineering}}: {{Companion Proceeedings}}}, author = {Lee, Seongmin and Binkley, David and Gold, Nicolas and Islam, Syed and Krinke, Jens and Yoo, Shin}, year = {2018}, month = may, series = {{{ICSE}} '18}, pages = {302--303}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {10.1145/3183440.3194981}, isbn = {978-1-4503-5663-3}, }
2017
- KIISEPYGGI: Python General Framework for Genetic ImprovementGabin An, Jinhan Kim, Seongmin Lee, and Shin YooJournal of Korean Institute of Information Scientists and Engineers, Dec 2017
@article{anPYGGIPythonGeneral2017, title = {{PYGGI: Python General Framework for Genetic Improvement}}, shorttitle = {{PYGGI}}, author = {An, Gabin and Kim, Jinhan and Lee, Seongmin and Yoo, Shin}, year = {2017}, month = dec, journal = {Journal of Korean Institute of Information Scientists and Engineers}, pages = {536--538}, langid = {korean}, } - SSBSEHyperheuristic Observation Based Slicing of GuavaSeongmin Lee and Shin YooIn Search Based Software Engineering, Dec 2017
Observation Based Slicing is a program slicing technique that depends purely on the observation of dynamic program behaviours. It iteratively applies a deletion operator to the source code, and accepts the deletion (i.e. slices the program) if the program is observed to behave in the same was as the original with respect to the slicing criterion. While the original observation based slicing only used a single deletion operator based on deletion window, the catalogue of applicable deletion operators grew recently with the addition of deletion operators based on lexical similarity. We apply a hyperheuristic approach to the problem of selecting the best deletion operator to each program line. Empirical evaluation using four slicing criteria from Guava shows that the Hyperheuristic Observation Based Slicing (HOBBES) can significantly improve the effeciency of observation based slicing.
@inproceedings{leeHyperheuristicObservationBased2017, title = {Hyperheuristic {{Observation Based Slicing}} of {{Guava}}}, booktitle = {Search {{Based Software Engineering}}}, author = {Lee, Seongmin and Yoo, Shin}, editor = {Menzies, Tim and Petke, Justyna}, year = {2017}, pages = {175--180}, publisher = {Springer International Publishing}, address = {Cham}, doi = {10.1007/978-3-319-66299-2_16}, isbn = {978-3-319-66299-2}, langid = {english}, }
2016
- SSBSEAmortised Deep Parameter Optimisation of GPGPU Work Group Size for OpenCVJeongju Sohn, Seongmin Lee, and Shin YooIn Search Based Software Engineering, Dec 2016
GPGPU (General Purpose computing on Graphics Processing Units) enables massive parallelism by taking advantage of the Single Instruction Multiple Data (SIMD) architecture of the large number of cores found on modern graphics cards. A parameter called local work group size controls how many work items are concurrently executed on a single compute unit. Though critical to the performance, there is no deterministic way to tune it, leaving developers to manual trial and error. This paper applies amortised optimisation to determine the best local work group size for GPGPU implementations of OpenCV template matching feature. The empirical evaluation shows that optimised local work group size can outperform the default value with large effect sizes.
@inproceedings{sohnAmortisedDeepParameter2016, title = {Amortised {{Deep Parameter Optimisation}} of {{GPGPU Work Group Size}} for {{OpenCV}}}, booktitle = {Search {{Based Software Engineering}}}, author = {Sohn, Jeongju and Lee, Seongmin and Yoo, Shin}, editor = {Sarro, Federica and Deb, Kalyanmoy}, year = {2016}, pages = {211--217}, publisher = {Springer International Publishing}, address = {Cham}, doi = {10.1007/978-3-319-47106-8_14}, isbn = {978-3-319-47106-8}, langid = {english}, }